We’ve been busily running a large performance study across clouds for the last few months, and although I’ve been learning immense things (how to setup and use Infiniband, and build applications and install drivers for new devices)! I haven’t taken any time to write anything down. Logically this makes sense, because a lot (most) of our findings belong in papers. But I did something fun last night, parallel but unrelated to the study, that I thought would be fun to share. Let’s start with a story.
V100 GPUs on Google Kubernetes
For our study, we needed to find a common GPU across clouds, and within our on-premises clusters. That turned out to be V100s. As I mentioned - these are “old” in the land of GPUs. A GPU from 7 years ago (2017) that is no longer in high demand is most definitely not going to be a focus for any cloud vendor. People won’t demand it as highly, so they can’t charge as much for it. While we had many different clouds and setups, one such setup turned out to warrant GPUs on Google Kubernetes Engine (GKE). When we tested earlier in the year the automated driver installers (provided via a daemonset) didn’t work, so I grabbed one on GitHub that seemed to do the trick. That installer stopped working a few months later when it was time to run the experiments. With some testing, we learned that using the “latest” version would work successfully to expose the devices! That looked like this:
time gcloud container clusters create gpu-cluster-32 \
--threads-per-core=1 \
--accelerator type=nvidia-tesla-v100,count=8,gpu-driver-version=latest \
--num-nodes=32 \
--machine-type=n1-standard-32 \
--enable-gvnic \
--network=mtu9k \
--system-config-from-file=./system-config.yaml \
--region=us-central1-a \
--project=${GOOGLE_PROJECT}
We had a working setup. All 8 GPU were being hit by applications, and (despite not having an OS bypass for connectivity) the results were OK.
V100 GPUs on Compute Engine
I created an analogous setup with Flux Framework on Compute Engine, deployed with Terraform. This required a custom build of the base image, and I strategically did it to be exactly the same as the containers to minimize friction between the two environments. But it didn’t work as I expected -only 4/8 GPUs were being used. That’s actually a story for another time (one I found the solution to after looking at Slurm and Flux source code and thinking about the contexts) but one of the strategies that was sane to try (of course in the wee hours of the morning) was to try and re-create the GKE setup where I knew it was working. This would mean deploying the GKE node as a VM and installing everything to it. Arguably, the same driver and base image that successfully used 8 on GKE should do the same on Compute Engine. And here we begin our (short) adventure! This was only an hour or two in the middle of the night, and actually well before I worked on the much harder of the two problems stated earlier. It was still great and worthy of a write-up in case anyone else has this need.
The Container Operating System
I first looked for the image family or other means to deploy the GKE base images in the Compute Engine “Create new Instance” and “Images” interface. I didn’t see any option there - my options were standard base OSes (Rocky, Ubuntu, Centos, etc) plus a series of HPC VM images (rocky and centos) and then others that weren’t of interest. For the HPC VM images, I had already tried several of these, but since they came with MPI built in, I found these installs to be a little borked. Minimally if I could get one working, there were strange conflicts when I tried to do a full install of MPI, which we needed. Instead, I decided I’d do more of a direct strategy - I could deploy a GKE cluster with the same setup, and then create a node shell (nsenter from a pod) into the node to look around. I could maybe do the same for the daemonset pod that installs the driver.
I very quickly learned that if you don’t specify a different image type when creating your cluster, you’ll get COS - the container operating system. I really love COS for spinning up a quick VM to do docker builds, but it’s challenging for anything else because there isn’t a package manager! This means that although I could look around at the driver install logic, this VM couldn’t be a contender for my custom build idea. The daemonset that I found online also was missing a Dockerfile or build logic. I also couldn’t shell into the driver pod to look around, because it was clearly a multi-stage build with a single binary and no filesystem. I decided to move on.
GKE with ubuntu_containerd
The other kind of VM that I had remembered could be deployed was an Ubuntu base. With some digging I found that you can edit the image type flag to gcloud container clusters create to be ubuntu_containerd. The same directory (linked above) with daemonsets dated that to be around 2016, which was before the V100’s existed, and not super promising. I decided it was worth trying to deploy that node type anyway to see what would happen. I learned quickly that I couldn’t specify the latest installer for the driver, but this worked:
time gcloud container clusters create gpu-cluster-ubuntu-1 \
--threads-per-core=1 \
--accelerator type=nvidia-tesla-v100,count=8 \
--num-nodes=1 \
--machine-type=n1-standard-32 \
# The important variable here is image-type.
--image-type=ubuntu_containerd \
--system-config-from-file=./system-config.yaml \
--region=us-central1-a \
--project=${GOOGLE_PROJECT}
But womp womp, when I looked at the pod created by the daemonset (that should install the driver to the node for me), it was stuck in init, with two containers not running. This was exactly what had happened even with COS before we specified the latest driver. But I couldn’t do that this time. The logical thing to do was to look at the logic of the init containers, which thankfully is provided when you describe the pod Note that there are two init containers, and we are stuck on the first (the get pods shows 0/2. That reason is this block:
if [[ "${GPU_DRIVER_VERSION}" == "default" ]]; then
echo "default" > /etc/nvidia/gpu_driver_version_config.txt
/usr/local/bin/ubuntu-nvidia-install
else
echo "disabled" > /etc/nvidia/gpu_driver_version_config.txt
echo "GPU driver auto installation is disabled."
fi
I can’t infer much from this aside from the fact that Google has maybe decided to not populate their metadata server with a version for this – an implicit statement “We do not want to support you using this old GPU in this way.” The text file being referenced in that config file did indeed say “disabled” (and I did a node-shell to confirm that). I first tried a kubectl edit to change that entrypoint to skip the metadata check and just run the command, but it doesn’t allow you to change the entrypoint). Then I had a really dumb idea.
“Can I just run that command?”
Yep. Do it!
kubectl exec -n kube-system nvidia-gpu-device-plugin-medium-ubuntu-mrlxz \
-c nvidia-driver-installer \
/usr/local/bin/ubuntu-nvidia-install
Once that ran (and successfully), then the next container, something called the gpu-partitioner, could run, and then suddenly, my nodes were reporting having 8 NVIDIA GPU available!
$ kubectl get nodes -o json | jq .items[].status.allocatable
{
"cpu": "15890m",
"ephemeral-storage": "49455357798",
"hugepages-1Gi": "0",
"hugepages-2Mi": "0",
"memory": "114308200Ki",
"nvidia.com/gpu": "8",
"pods": "110"
}
Of course, I needed to test this, so I created a teeny tiny Flux Framework (Flux Operator) MiniCluster and ran an application that eats GPU like a hungry gorilla called mt gemm. Lo and behold, I saw all 8 GPUs being used. Excellent.
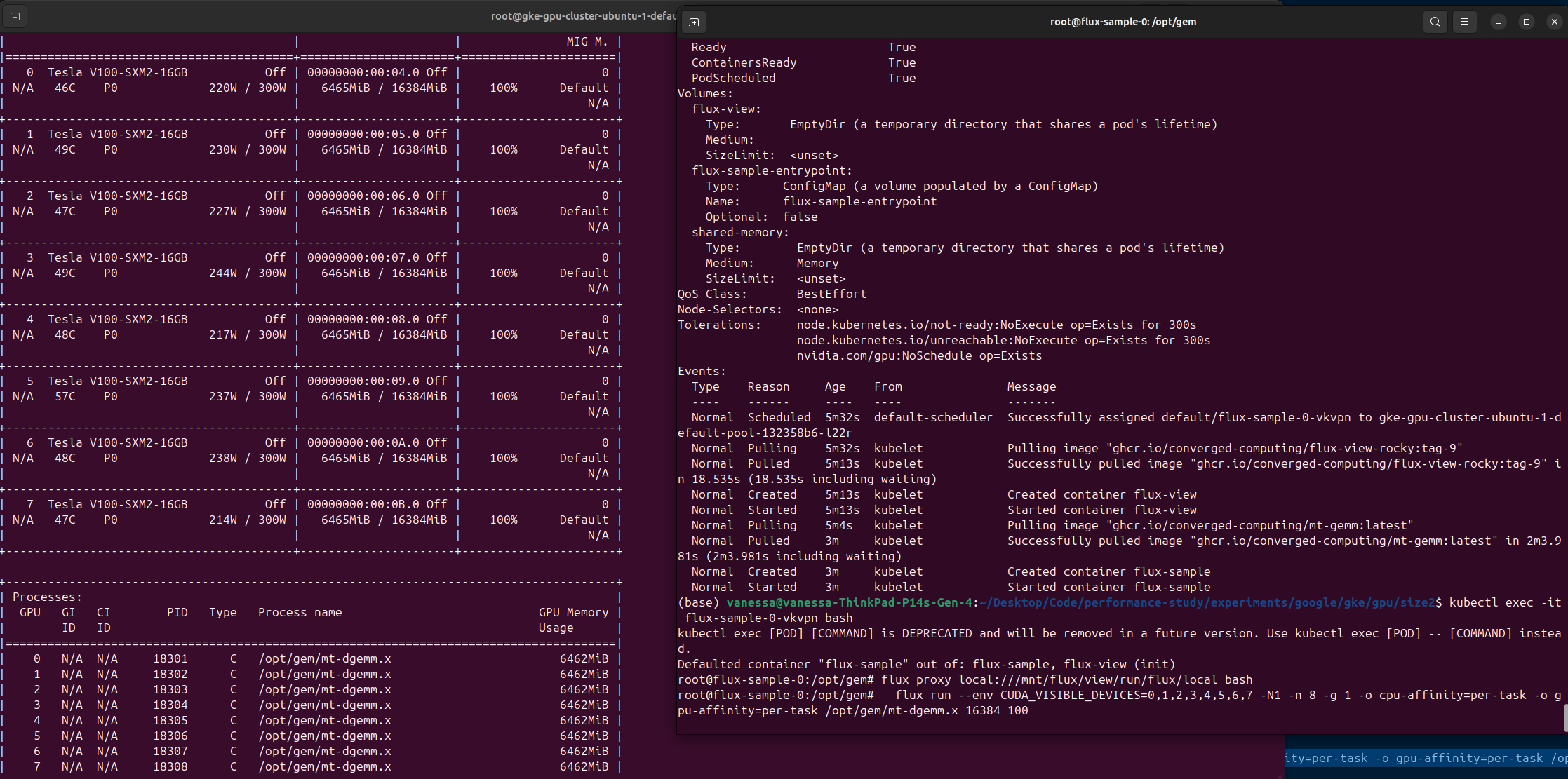
And just to be clear, on the setup I was debugging (with the error that warranted me to reproduce a setup I knew to be working as an analogous VM), the output of nvidia-smi (on the left) would only show the top 4 GPU being used. But for the purposes of this post (where I’m not going to talk about that bug) the important note here is that this is a means (a hacky one, albeit at best) to get V100s working with the Ubuntu base VM.
VM with ubuntu_containerd
I next removed this node from the pool, and then was able to stop and image it. Then I was able to boot it up, install all my Flux and API things, and have a custom build VM that was based on this particular image. And the devices still worked when I used that VM in my terraform setup! 🥳 I ultimately am not using it there (because I figured out the harder, second bug that I was looking at this for) but I thought it was pretty neat to investigate the ubuntu base init containers, plow through some things, and get working GPUs (for a fairly old GPU model) using what is probably an unsupported driver version and GPU combination. I’m actually not sure why their metadata server didn’t populate with a version.
And that’s the entire story! Speaking of our study, I need to get back to that. I took a short break to write this, but the remainder of work is not going to do itself.
Suggested Citation:
Sochat, Vanessa. "Adventures of Ubuntu GKE with V100s." @vsoch (blog), 11 Jun 2024, https://vsoch.github.io/2024/ubuntu-v100-gke/ (accessed 23 Mar 26).