This is a first prototype to get GPU devices working in User-space Kubernetes, or Usernetes. I am calling it a prototype because it is a “works for the first time” and will be improved upon. For our use case, we will be testing and using on clouds that have NVIDIA GPU devices, however we will need to support other device types in production, and this will be future work. I want to create this write-up while everything is fresh in my mind, because I just had 2.5 days of working through the complexity of components, and learning a lot.
A bit of background
We want to test User-space Kubernetes “Usernetes” ability to run a GPU workload, and compare between Kubernetes (as provided by a cloud) and the equivalent user-space setup deployed with the same resources on the VM equivalent. Google Cloud has excellent tooling for deploying GPU and installed drivers for GKE, so I was able to get this vanilla setup working and tested in under an hour. The setup of the same stack, but on user-space Kubernetes on Compute Engine deployed with a custom VM base on Terraform, would prove to be more challenging.
I’ve designed various driver installers for previous work, including infiniband on Azure Kubernetes Service and more experimental ones like deploying a Flux instance alongside the Kubelet. NVIDIA GPU drivers are typically installed in a similar fashion, in the simplest case with nvidia device plugin but now NVIDIA has exploded their software and Kubernetes tooling so everything but the kitchen sink is installed with the GPU Operator. Getting this working in user-space was uncharted territory, because we had two layers to work through - first the physical node to the rootless docker node (control plane or kubelet) and then from that node to the container in a pod deployed by containerd. Even just for the case of one layer of abstraction, I found many unsolved issues on GitHub and no single source of truth for how to do it. Needless to say, I wasn’t sure about the complexity that would be warranted to get this working, or if I could do it at all.
Resources and Cloud
For this environment, we are working on Google Cloud, and specifically with V100 GPUs, because I can get them in very small numbers (on the order of 1-4 per node, and for a few nodes). To develop with a few GPU on a node it would be a reasonable cost, about $12.00/hour (for reference, the cost of each GPU is $2.48, and then the corresponding instance is ~1.75). This is good example of how tiny bits of resources can go a long way if you are a developer, and (personally speaking) I like clouds best for development environments that I can control over all other use cases. I needed these up for a long time for development, and created easily 50 different setups over a few days. When I had nodes up for most of a day, the total cost was about $150.0. When I realized I would need to do a lot more work, I cut down the number of GPU per node to 2 (my pytorch workflow has a master and worker).
Virtual Machine
When I first started, I took a strategy of using what Google provided. When you select the V100 and navigate to OS, it gives you an option to select one of their ML optimized images. These images are very old (Debian 11 is the newest, which I think dates to 2021) and they only go up to CUDA 12.3. I thought that would be OK to start, but in retrospect it made the environment more error prone. I had to remove and reinstall docker as rootless, and there wasn’t transparency about how the initial Debian base was customized. A good strategy for building these images is to start from an empty slate to the highest extent possible to maximize transparency of what changes have been made.
What ultimately worked was to start with an ubuntu 24.04 image and install my own drivers and CUDA, and then I could choose versions selectively (CUDA 12.8, and I seem to remember the driver version being used was 560.xxx). I was a bit nervous about this because the recommendation was lower than that for the V100 on the n1-standard family, but their provided ML image wasn’t working for me so I had an open mind. You can see the driver install commands here.
Usernetes
The install of Usernetes was typical. You need to enable several kernel modules, cgroups v2, and install a rootless container technology. I chose rootless docker, although on HPC systems you would be forced to use podman. I also set most limits (e.g,. nproc, memlock, stack, nofile, etc.) to unlimited.
One gotcha in this setup that is specific to Google Cloud is how logins to machines are handled. You will typically get OS login, or otherwise login as your email / username. The problem with this is that you get assigned a really high id, and one that isn’t present for any ranges in /etc/subuid. What happened for me on the first day is that rootlesskit was failing (somewhat silently, or at least I missed looking in places to check for it) so I was running rootful docker. The problem was not only that uidmap wasn’t installed, but that the user didn’t have a range. It was actually the debug output of nerdctl that I tested on a whim that pointed me to the issue with the setup, and shout-out to Akihiro for again excellent work. I decided to use the default ubuntu user, with id 1000, akin to what I did on AWS and Azure.
Rooty Docker!
Using “ubuntu” poses a bit of an issue for ssh-ing in. The “gcloud” client is not going to easily allow ubuntu. What I needed to do was first ssh in with my os login, add a public key for my machine to /home/ubuntu/.ssh/authorized_keys and then ssh in as ubuntu. For the terraform setup that doesn’t expose an ephemeral IP, I needed to edit the instance with the control plane, to add an ephemeral IP for ssh.
As a side note - it wasn’t hard getting GPU devices to work with rootful User space kubernetes (yeah, that doesn’t make sense, does it)? I couldn’t use this setup, even as a mock, because rootful breaks usernetes on a multi-node setup. I was able to create a GitHub CI test that reproduces the issue, and hopefully it will be fixed soon! I’m thinking it’s probably related to a rootful docker not properly working with slirp4netns, but I am not an expert there and haven’t looked into it.
The last customizations for docker needed on the host VM were to install the nvidia container toolkit “nvidia-ctk” and configure it to use the docker runtime, and with CDI (the container device interface). For this step I allowed it to generate devices for the development machine I was on, and note that these need to be regenerated when that VM base is used for Terraform.
Docker Compose
Most of the issues on GitHub and instructions for rootless docker and NVIDIA GPU had one indirection in mind - getting the devices on the host to show up in a single docker container. We have two indirections, because we need to map the host devices into a node on the VM running the kubelet, and then that node (a rootless docker container) has containerd that needs to further pass those devices to containers running in the User space Kubernetes cluster. This means we need to solve the problem twice, and essentially have every component in the stack (e.g., the nvidia runtime config file and nvidia toolkit install) duplicated. I found a lot of GitHub issues (here is one open since 2023) that would suggest setting no-cgroups = true in the nvidia container runtime config at “/etc/nvidia-container-runtime/config.toml” and I did try that, but found that it failed after the second indirection.
A Gotcha with the Nvidia Runtime
Many instructions directed to tweak the nvidia runtime to have “cdi” enabled as a feature, and then point to the nvidia-container-runtime executable for the runtime. In fact, there is a command to easily do that. What I realized was that with rootless docker, it wasn’t picking up the default location of the daemon.json, or where the user space one was expected to be. I looked into the service and found that it was running “/usr/bin/dockerd-rootless.sh” and tweaked the entrypoint of that file to explicitly target the config, like this:
exec "$dockerd" "--config-file" "/etc/docker/daemon.json" "$@"
That was a manual change I had to make on the VM (that is saved as the base image for Terraform). It’s important to validate that the nvidia runtime is present (detected) along with rootless before moving forward:
docker info | grep -i runtimes
Runtimes: io.containerd.runc.v2 nvidia runc
docker info | grep root
rootless
You should also test the nvidia runtime before moving forward. You should be able to use it with a vanilla ubuntu container and have “nvidia-smi” working and seeing devices!
docker run --rm -ti --device=nvidia.com/gpu=all ubuntu nvidia-smi -L
GPU 0: Tesla V100-SXM2-16GB (UUID: GPU-798e9725-623d-ca7f-f15d-b1908ec8bb0d)
GPU 1: Tesla V100-SXM2-16GB (UUID: GPU-be5719da-cd52-8a40-09bb-0007224e9236)
docker-compose yaml
The tweaks to the default usernetes docker-compose.yaml are minimal. I had tested added permissions (caps, for example) but ultimately just needed to specify using the nvidia runtime, and then the list of devices. You can see the setup here, and note that I think (but have not tested) that adding “devices” vs. the “deploy” directive do the same thing. Note that if you try to start the control plane (or a worker) with “make up” without using the nvidia runtime and asking for devices, without the “no-groups = true” you will get an error, specifically this one about bpf_prog_query with failed permissions. That is another issue that has been open since 2022. 🙃
Usernetes node
A Usernetes node can be the control plane or a worker. The general procedure for the control plane is to bring it up, run kubeadm init, install flannel, make the kubeconfig, and then prepare a join command to send to workers. The worker nodes also need to be brought up with the same setup, but then they just need to have the join-command (it’s a text file that is executed as a command for kubeadm join). The additional step I needed to add to this was a Makefile command to “make nvidia” that would setup CDI to be used inside the node.
.PHONY: nvidia
nvidia:
$(NODE_SHELL) nvidia-ctk system create-dev-char-symlinks --create-all
$(NODE_SHELL) nvidia-ctk cdi generate --output=/etc/cdi/nvidia.yaml --device-name-strategy=uuid
$(NODE_SHELL) nvidia-ctk cdi list
$(NODE_SHELL) nvidia-ctk config --in-place --set nvidia-container-runtime.mode=cdi
$(NODE_SHELL) nvidia-ctk runtime configure --runtime=containerd --cdi.enabled --set-as-default
...
$(NODE_SHELL) systemctl restart containerd
In the above, we create a set of symlinks that I found were needed in practice, but I would see errors if they didn’t exist. For the GPU operator, I found that there was an environment variable in the validator that needed to be set to disable trying to make them, which would fail in usernetes with a permissions error. I didn’t wind up pursuring that path further (using the GPU Operator) because it was highly error prone, and making changes that led to a broken state for Usernetes. We are also generating the cdi file “nvidia.yaml” in “/etc/cdi” and setting the nvidia container runtime mode to use it. Finally, we are configuring the nvidia container runtime to work with containerd, and (still) with CDI enabled. The sed commands (not shown) are uncommenting and enabling different settings I found that would (at least at face value) possibly help in rootless mode. Finally, we restart containerd.
It took me a lot of testing and learning (I have no experience with CDI or working with these tools beyond installs of the nvidia device plugin that have just worked on clusters in the past) to get to the above. You can see the full Makefile here. At this point, we have the node configured also with the nvidia container toolkit, and containerd updated (and restarted) to use it.
NVIDIA Device Plugin and GPU Operator
It’s typically easy to apply the nvidia device plugin to have devices detected and working. This gave me quite a bit of trouble, because at first (when I wasn’t using CDI) it only detected anything when I specified “tegra.” That would have the labels show up on the nodes, but then when I tried to create pods they would fail not knowing what tegra is (and understandably, that’s the wrong setup). Changing it to use nvml would fail to find the library, and “auto” didn’t work at all (at least at the onset). Before I got the CDI just right I went through half a day of going back and forth between using (and trying to tweak) this yaml file and testing the GPU operator, and found a lot of really weird states.
Several times I could deploy the first, have the GPUs show up, but then fail in the cluster, and then apply the GPU Operator. A few times that seemed to work, and other times (most times) it just led to more errors, and not even getting so far to get labels for the GPU. I don’t know how this worked once, but when I tried to reproduce it, I would get containerd operation not permitted errors, along with an error about a PID. There were at least 5 times when something would work, and then I would save an image of the VM with the changes, bring up the Terraform setup to reproduce, and reach the “moment of truth” with deploying pytorch and be faced with another new error. That usually felt bad. 😞 My best guess based on this work is that we were having interactions between components and slight differences in GPU operator components coming up that led to inconsistent state.
What I ultimately decided is that the GPU Operator was too complex to understand easily. I tried customizing the values.yaml install with helm to disable un-needed components (for example, I don’t need MIG here to split GPUs, and the V100s don’t support that anyway) to try to simplify (and make it understandable) but my intuition told me that it was too complex. I didn’t like that it seemed to break the setup, give me inconsistent states, and there were so many init containers and dependencies it wasn’t clear if there were race conditions. All I can say is that on the rare cases something started working, it didn’t reliably reproduce in this rootless setup. In several of those cases it worked for a first run, and then broke for subsequent with new errors. This is what led me to not use it, and focus on the details of the CDI and the simple device plugin daemonset deployment. That ultimately worked like a charm, despite not being recommended for production setups.
The Application
The ML app wasn’t without issues. Specifically, the entrypoint for the master or a worker might look something like this:
python3 /opt/pytorch-mnist/mnist.py --epochs=10 --backend=nccl --batch-size=128
I hit several errors about not finding GPUs, or (in the case of rootful Docker with usernetes) the networking never working. I had a mangly device error that was resolved when I updated the container to the latest version (now 2 years old). Another unexpected issue was with respect to data. I had prepared data to use from the old container, and when it was attempted to be used with the newer version, it wouldn’t validate and would try to download. Given that the download links weren’t working at the time, I couldn’t run anything. I had to ensure that the data matched the container. There is more on that here. We ultimately build our own container with the data to ensure it is available, and we won’t take time during our experiments to download it. Side note - in that exercise I learned that I could convert a Python egg to a zip, unzip to explore, and then make changes and repackage into an egg! YOLO!
Summary
The final setup is using an ubuntu 24.04 base with CUDA 12.8 and drivers 560.xxx, and using a strategy of rootless docker for usernetes with the nvidia runtime exposing devices via CDI. Setting no-cgroups to true or not using the nvidia runtime will not work, either due to needing cgroups later or the bfp permissions error I noted earlier. Once in the container, we need to again prepare CDI to be used with containerd, and ensure that we generate symlinks in advance. The GPU operator results in a broken state, and the nvidia device plugin, on its own, can best expose devices on the nodes to be available to the pods. Here are a few images for posterity that show everything working. First, the nvidia device plugin:
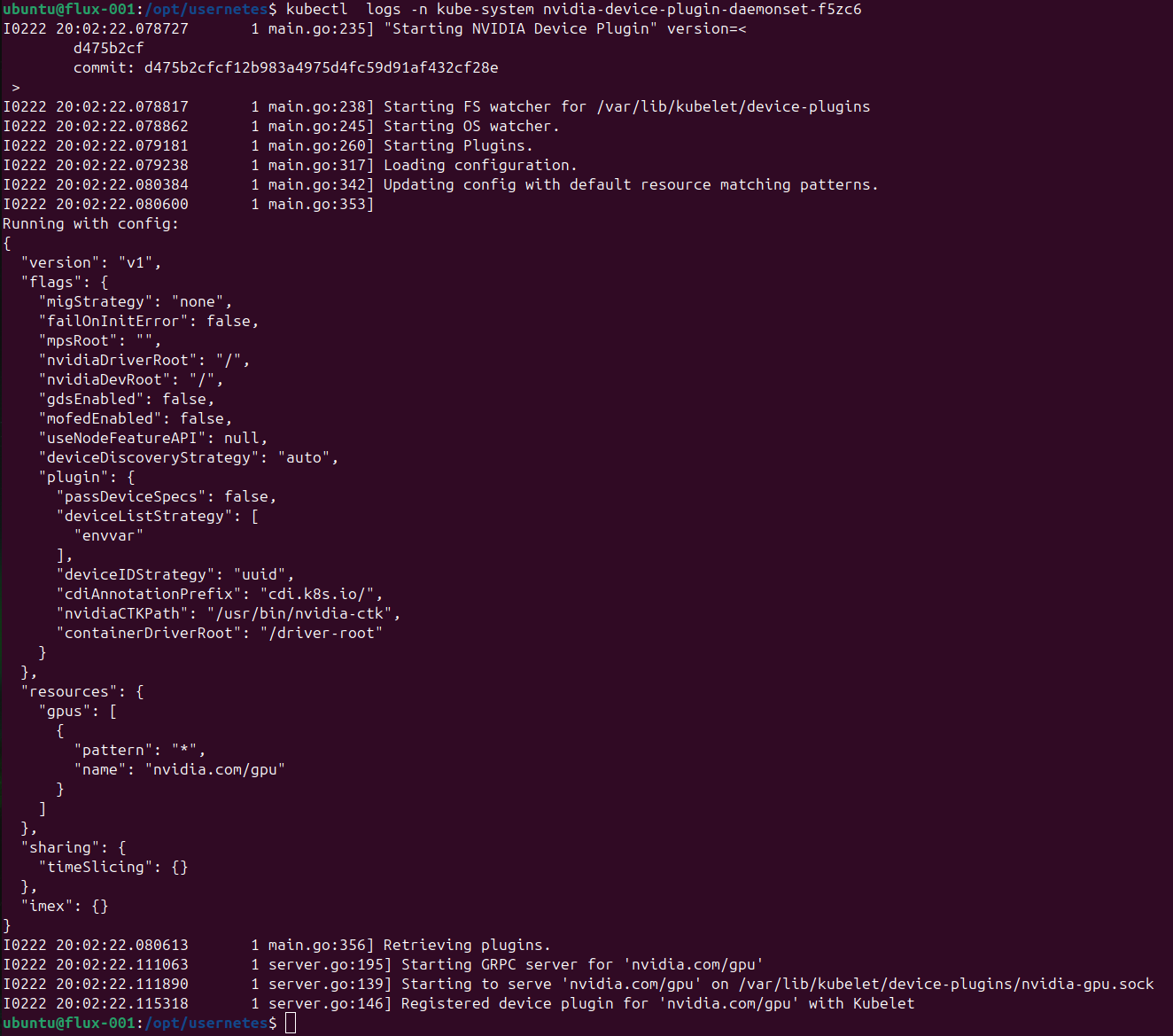
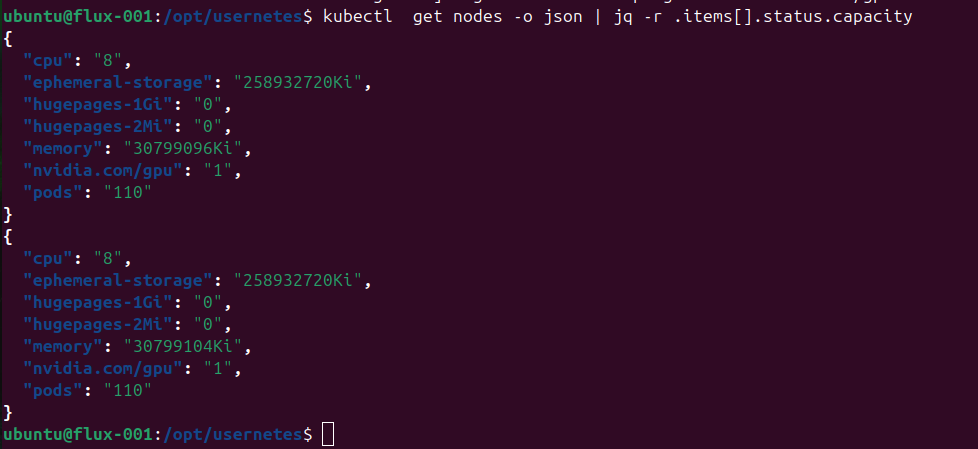
And this is when the devices show up (just one GPU) on our tiny nodes. For context, we can’t get many GPU on Google Cloud, so we are maximizing the number of GPU per node, since we primarily need to test Usernetes for network.
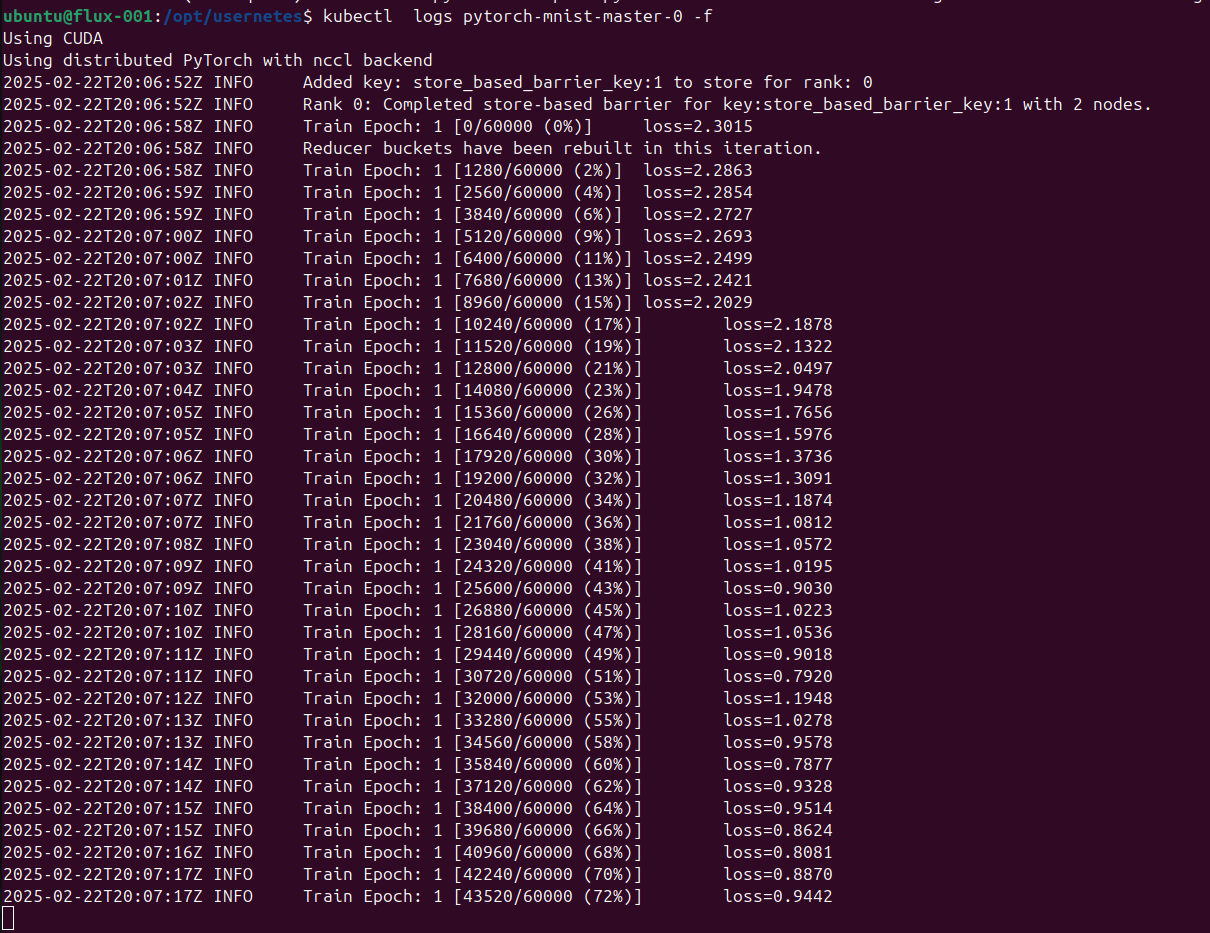
And pytorch working - go epoch, go!
Reflecting
This process from zero to working that lasted 2.5 days (with a bit of sleep between days) was uncharted territory, and I knew would be challenging from the getgo. It is an experience that I must strangely enjoy? I say this because I have moments of joy and anguish, and several times in the period of time I “decided” to give up. But somehow (even when there are many other things I should have be doing) I found myself continually returning to the setup. It meant waking up with “just one more idea” or bringing down a setup, finally eating, and then during mind wandering deciding that I wasn’t done yet.
I don’t know if this is mental strength or just stubbornness (I think likely the latter). It’s a brute force approach, when I think about it, because I almost refuse to stop until I physically fall over. This didn’t happen the first night, but did the second night. It’s also a kind of problem that I know I won’t get help with. Not to get too philosophical, but I’ve realized through life experience that if I want something done, I need to do it. If I want change, I need to figure out the steps to take and take them. It’s easy to defer responsibility or blame, and I won’t do it. Often it’s not productive, because it accomplishes nothing. That kind of approach applies in everyday life when it comes to making choices about taking care of oneself, and also for learning and solving hard problems. Knowing this was an important problem to solve for my institution, team, and community, even the start of a solution, I felt that responsibility. I’m grateful for the inspiration and support I get from my small team to have the inner fire that drives me. It makes the work challenging, and when we solve problems together, fulfilling and fun.
All in all, I can’t say what the essential fix was, but I will say this is a complex setup. In retrospect, my advice here is to follow intuition, try to build components that you have the most transparency (and control) over, and choose simplicity over complexity over what can be software bloat for a simple use case. And on that note - I am going to leave my dinosaur cave and go outside! And then likely I really do need to come back and work on those slides, which I have been very successfully putting off for 3 days now. 😉
Suggested Citation:
Sochat, Vanessa. "Rootless User-Space Kubernetes with GPU." @vsoch (blog), 22 Feb 2025, https://vsoch.github.io/2025/rootless-usernetes-gpu/ (accessed 23 Mar 26).