Container discoverability is a problem. I should be able to do a search (somewhere, how about Google?), and find what I’m looking for. There must be a webbing of metadata that can span Github repositories, container registries, and pretty much any webby place where a container might be found to help with this. I’ve had vision for how this could work using already existing things, and working dilligently to exemplify it. First, let’s talk about what I wanted to do.
A Vision for Discoverability
I want to define a “Container,” meaning the Image and build recipe / specification (insert your favorite word for a text file here) in schema.org so that we can then discover and query the (currently) expansive and disorganized universe of containers. This comes down to:
- 1. Container Definition in Schema.org
- 2. Programmatic interaction with schemas
- 3. An Example Implementation
- 4. Deployment
The definition of a container (step 1) in schema.org means that we can programmatically (step 2) tag them, have it done automatically for single container registries and repositories (step 3) and then have these metadata embedded in html pages to be discovered by search, akin to how Google Datasets work.
1. Container Definition in Schema.org
Schema.org is an ontology, or description of entities and relationships between them, that attempts to describe kinds of things in the world, literally from type Thing to type Volcano. The value isn’t necessarily being able to define a list of attributes for any one thing, but for being able to make inferences over the graph, and answer weird questions about how types of thing1 and thing2 relate to one another. Thus, a container definition in schema.org comes down to defining representations for Containers in this graph. I want to know how my Container recipe (Dockerfile) relates to Volcanoes, for example. While imperfect, after early discussion with schema.org, I went to the OCI community for some hard core expertise, and I came up with an early proposal:
Thing > ContainerImage
Thing > CreativeWork > SoftwareSourceCode > ContainerRecipe
While the name “ContainerRecipe” is up for change with many good ideas from the OCI list, the general idea and organization is presented. If you are interested in rationale for this proposal, I summarize it here. If you want to jump back in on the OCI thread, you can do that here.
2. Programmatic interaction with schemas
Great! We have a nasty looking yml or json-ld, but I’m a software developer. What am I going to do with that? I will again present this as a list of use cases. People in this industry / academic world seem to talk about these “use cases” a lot.
What are we trying to do again?
The high level goal is to make it easy to tag datasets, containers, and other software to be accessible via Google Search as a dataset (or similar as Google develops these search types) or programmatically via an API. This means that:
If I’m a researcher
- I can search Google to find datasets or software of interest based on schema.org organization
- I can use the corresponding search API to find a subset of datasets / software for my research
If I’m a developer
- I can develop tools for my users to find content of a particular type
- I can provide users with recipes to guide them how to extract metadata that I need for my tool
- I can validate what they provide me with
- I can build software that understands the categorization and organization of a particular type
For the last points, you can imagine validating a dataset contribution, and then
using the known organization to move it from some local to a cloud storage. You can imagine
writing software that expects a particular set of metadata, and then being able to programmatically
validate if it’s been provided. You can also imagine the simpler use case - just having
the metadata to drive search and interesting analyses about your thing1 and thing2 of interest.
For my production use case, I would add some simple template rendering for Singularity Hub containers so that there was a json-ld object for search to find, provided with each container.
How do we interact with the schemas?
I asked schema.org about a Python client, and the answer was something like “well use rdflib” and then it was tagged with “Good Question.” I wasn’t asking a question, I really wanted a solution. And I wanted something a little simpler, and something that wouldn’t require me to have expertise beyond what a typical data scientist or research might have (ahem, Python)! I wrote a schmeaorg module to accomplish these goals, and I hope that others interested in this kind of interaction with the specifications might contribute to what I’ve started. Briefly, I’ll show you how easy it is to interact with a definition, and see here, for detailed walk-through and more robust examples.
from schemaorg.main import Schema
softwareCode = Schema("SoftwareSourceCode")
Specification base set to http://www.schema.org
Using Version 3.4
Found http://www.schema.org/SoftwareSourceCode
SoftwareSourceCode: found 101 properties
Add some properties…
sourceCode.add_property('description', 'A Dockerfile build recipe')
You can optionally validate it against a recipe for some set of required properties you need (not shown here) and then save the dumped metadata into just json, or a json-ld template.
sourceCode.dump_json()
from schemaorg.templates.google import make_dataset
dataset = make_dataset(sourceCode, "index.html")
This was pretty cool! Now I could interact with schemas. Done. Moving on.
3. An Implementation
Ok, good, we have specifications, and we have a way to interact with them, now we need to create some example extractors! As another reminder the input here should be some container recipe (we will use a Dockerfile) and the output should be an html page with embedded json-ld of metadata. I came up with a Github repository of example extractors toward this goal. Here is a quick jump to see an ImageDefinition, or an extraction from a Dockerfile to describe it!
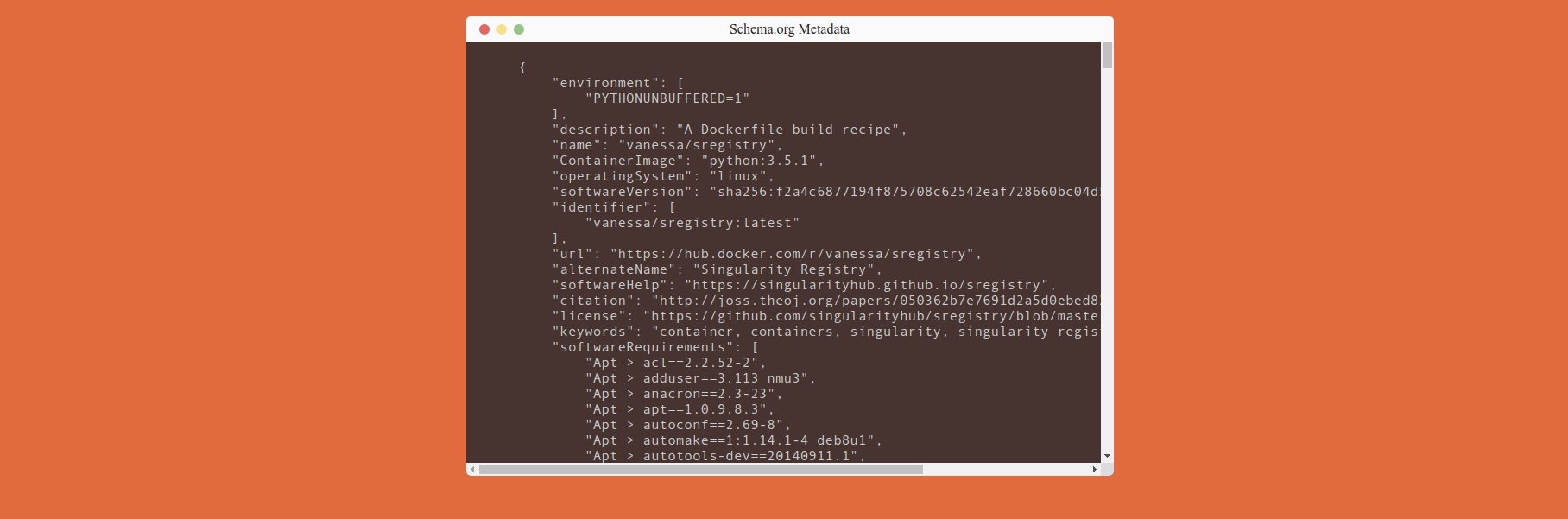
The template is pretty, but the important part is to look at the “View Source”
Now, if only the Google bots could index this, we could easily generate the metadata for tooons of places! You can look at any of the subfolders in the repository to see the extract.py, the recipe.yml, and in the case of a custom specification, a specification.yml file.
$ tree ImageDefinition/
ImageDefinition/
├── Dockerfile
├── extract.py
├── index.html
├── README.md
├── recipe.yml
└── specification.yml
This metadata would go into an index so that the container recipe, wherever it’s being searched, would have its metadata indexed by a search engine. Because a massive search engine can do eons more for discoverability than any single website or registry. Help us OOgly-one-canGoogley, you’re our only hope!
Where would this be run?
We could best run this with a continuous integration step, meaning that metadata for a container is extracted with each change to it. We could also run it at build time for a container registry, or an institution or user could use the software locally for research. If you already have a container registry, then you can just render some of your metadata into the page.
4. Next Steps
I hope you see the next steps! For each of these, I hope that you can weigh in or help. There is only one of me. It gets lonely a lot. I don’t have a team, I just have Github issue boards and random lists of developers. Give a dinosaur some support, and friends! We can do the following:
Harden the schema.org specification.
I had a meeting scheduled in September for October, and it was cancelled and rescheduled for January. I was really sad about this for a while, and then it motivated me to keep trying. I hope that some day we can do better. The issue that I now opened almost 2 months ago is here. Please jump in!
Decide on a name for the recipe
As I alluded to earlier, we could call a recipe a ContainerRecipe, an ImageDefinition, a BuildPlan, or pretty much anything else! To the community, how would you like to decide? Is a vote the easiest way? Okay let’s do that. It’s orange for Fall / Halloween / November!
Extract en masse!”
This is what I’ve been wanting to do from day 1! Given the definition and a database of say, Dockerfiles (I have a Github repository handy and in mind!”) We can do an extraction en masse, and then better engage with Google tooling (or create our own) to answer questions like “How do I develop search around this?” And then boum, containers are discoverable, done.
Questions for You
Next steps also include contributing to the schemaorg module, if this is of your interest. What other kinds of templates or features do you want to see? Please reach out and let me know.
- Google - I want to make container search happen. Tell me what I need to do.
- Schema.org - how can I help you to improve your software base so that we can really take advange of all these Things?
- All - what kinds of tools do you want to see around discoverable containers? Where do you want to extract metadata for your containers, and/or serve it?
Suggested Citation:
Sochat, Vanessa. "Container Metadata with Schema.org." @vsoch (blog), 05 Nov 2018, https://vsoch.github.io/2018/schemaorg/ (accessed 14 Jul 26).