We’ve recently been interested in coming up with ways to improve user interaction for AskCI. Specifically, we have a “Question of the Week” that we intended to use to engage users, but historically it doesn’t seem to encourage much participation.
Groups can grow community
I think we can do better - and it comes down to figuring out how to make the site more fun. What we really need is to grow a sense of community. How might we start to do that? It actually comes very easily by way of how our particular site is structured - we have different categories that correspond to institutions like “Harvard” or “Stanford.” It’s then incredibly easy to create groups, and in fact have users automatically added based on their email alias. I was able to set this up, with one group for each category board, resulting in 9 groups that were institution specific, in addition to the typical groups based on trust levels and permissions.
In fact, if you are part of AskCI, you can very easily visit the groups page and join your group(s)!
Healthy Competition
Once we have these groups, wouldn’t it be fun to base a lot of activities on the site, or incentives for participation, in a competitive context? If we could give our prizes, for example, for the top group or individual to contribute in some way, that would be really fun. Having fun is probably the only reason I do anything these days, so this is a good incentive for me. With that in mind, I decided to explore the Discourse API, and very happily found that I could retrieve user and post information with the simple use of an API token.
Programmatic Metrics
Of course I would want this to be totally automated. Even navigating through the stats on a weekly basis to look at specific fields I find arduous. I started to write a Python script to parse the various endpoints, but decided to have a little more fun by challenging myself to do it with Ruby. Discourse is implemented in Ruby, so this felt like the right thing to do, in spirit. I’m obviously not a ruby developer, and would need to figure out the basics from scratch. It probably took me 10 times as long, but I came up with a simple script! Here it is if you are interested. Basically we:
- Get credentials from the environment
- Get a listing of groups
- Get a listing of users per group
- Calculate contributions (posts and replies) for each user, and each group
- (Contributions are limited to the previous month)
- Save results to file (yaml)
The above can be run locally, or via a Docker container, if your preference is not to install dependencies on your host. It basically comes down to exporting credentials:
export DISCOURSE_API_TOKEN=xxxx
export DISCOURSE_API_USER=myusername
and either installing and running locally:
$ bundle install
$ ruby user-counts.rb
or building the container, and running it instead:
$ docker build -t vanessa/discourse-ranking .
$ docker run -it -e DISCOURSE_API_KEY=${DISCOURSE_API_KEY} \
-e DISCOURSE_API_USER=${DISCOURSE_API_USER} \
-v $PWD/data:/code/data vanessa/discourse-ranking
Looking up members by group
Calculating contribution totals for last month...
GROUP: admins
aculich
christophernhill
discourse
eibrown
...
The output folder will have a set of data files, each with a sorted list of users or groups, with contributions from the last month.
data/
├── groups-2019-08-13.yml
├── groups.yml
├── users-2019-08-13.yml
└── users-per-group-2019-08-13.yml
Complete code is is here with the repository, and the rendered html plot is at hpsee.github.io/discourse-rankings.
Plotting the Result
This is our first test run, and mind you that groups were just generated recently. We have a large percentage of the user base that hasn’t been associated with any particular group, so it’s likely to be a bit off. But here is the group rankings:
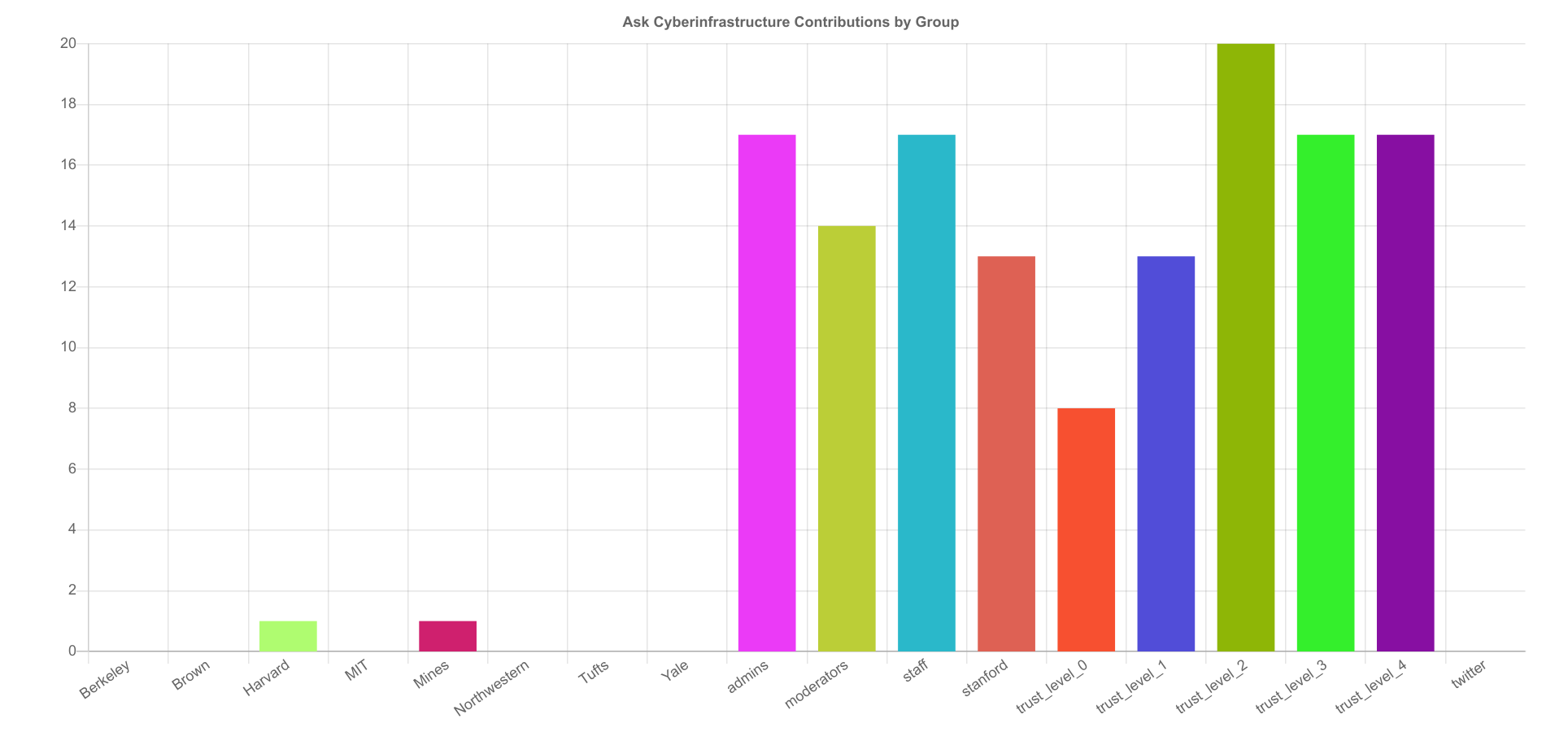
Notice anything interesting? I’ll share what I see.
Group Memberships
Most of our new groups don’t have a large number of members. Take a look at the data - this is users per group:
$ cat data/users-per-group-2019-08-13.yml
---
- - Berkeley
- 6
- - Brown
- 12
- - Harvard
- 11
- - MIT
- 2
- - Mines
- 2
- - Northwestern
- 3
- - Tufts
- 2
- - Yale
- 5
- - admins
- 16
- - moderators
- 29
- - staff
- 34
- - stanford
- 5
- - trust_level_0
- 100
- - trust_level_1
- 100
- - trust_level_2
- 78
- - trust_level_3
- 75
- - trust_level_4
- 48
- - twitter
- 1
The largest groups are the discourse defaults related to trust level or permissions (e.g., “trust_level_1”, “moderators” or “admins”), and then the larger of the user boards might have 10-12, and then closer to 5 or fewer. What this tells us is that
user groups are not well defined.
We need to first do a good job to advertise groups to our community, and have those with non-institution email addresses self assign themself to the right groups.
Contributions
While we can’t say which institution group is posting the most, we can look at the posts based on trust level and see some mixed news! It’s unfortunately the case that admin and staff tend to be also included in lower trust levels (e.g., trust_level_0 through trust_level_0) so based on the fact that we see the largest number of contributions from moderators and admins, it’s very likely the case that most site posting is done by these groups. This means that we really need to do a better job of encouraging participation on our site - not through artificial means, but genuine interest and incentive.
Conclusion
When participation is a bit dry, it usually comes down to incentive. Incentive can be driven by prizes and fun, but it’s hugely driven by a sense of community. If you feel like part of a community, you will want to participate, because it’s important to you. It’s as simple as that. We haven’t yet created this sense of community on our site, but I suspect it’s something we will be working on in the near future. And on that note, I hope that you enjoyed this post! I had a really fun time today learning some ruby, and writing this up. I realize that ruby plugs really well into web interfaces, so I might next try generating the plot directly from it.
Suggested Citation:
Sochat, Vanessa. "Discourse Contribution Rankings with Ruby." @vsoch (blog), 13 Sep 2019, https://vsoch.github.io/2019/discourse-rankings/ (accessed 14 Jul 26).