I’ve always wanted to create an interface that would make it easy to search all of my public repositories, and in fact, the piping is ready on GitHub pages to allow for this, because you can easily iterate through your user account or organization “public_repositories” that are present on the GitHub pages repository metadata:
{% for repository in site.github.public_repositories %}
* [{{ repository.name }}]({{ repository.html_url }})
{% endfor %}
If you don’t want to read about the process, here it is! Otherwise, continue reading.
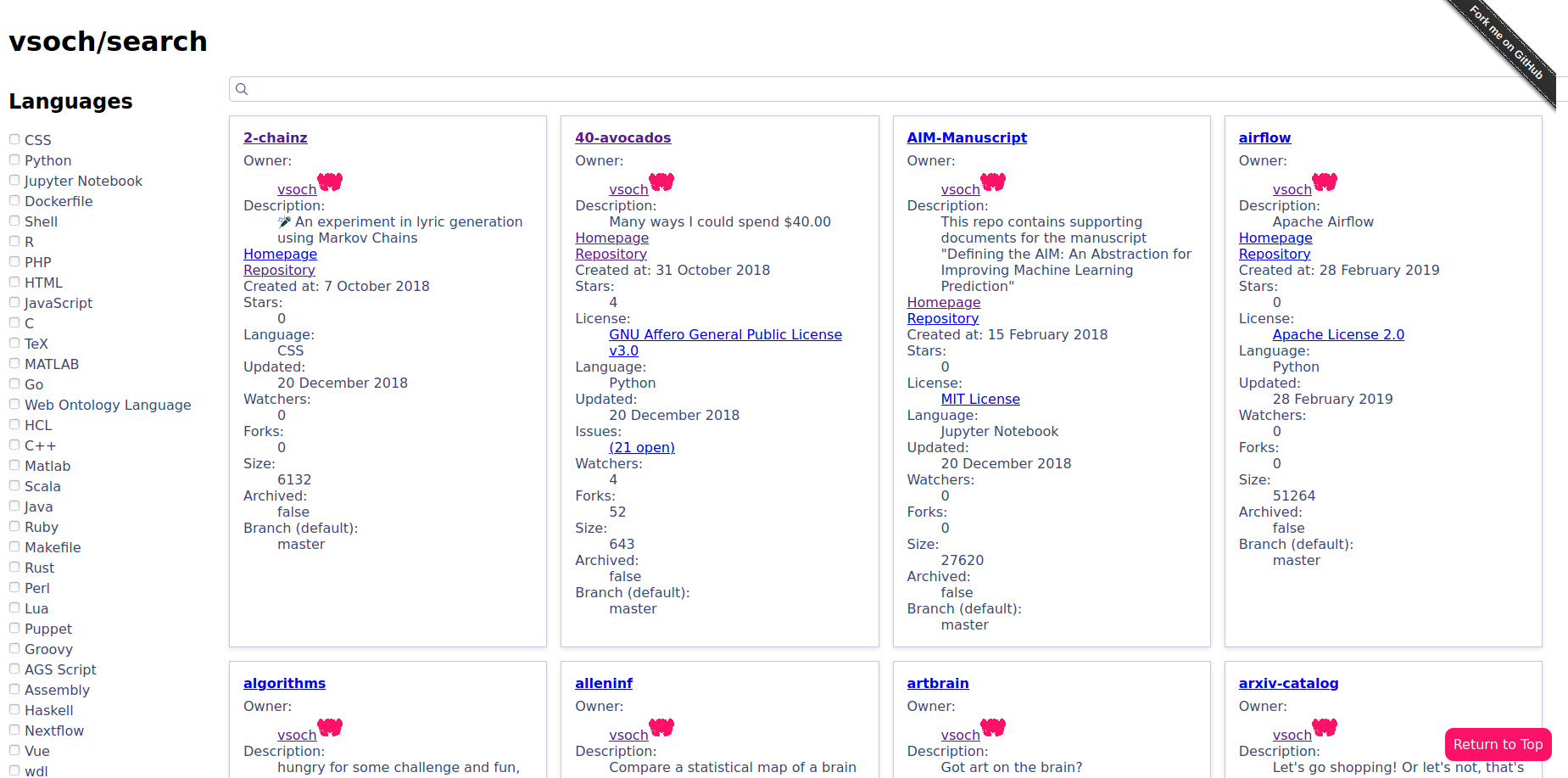
The search interface has also been added as a template for Stanford Research Computing RSE Services. If you are an academic lab or user that has many repositories you’d like to make easy to browse, this is a nice solution for you.
A Beautiful Interface
I’m not a web designer, so largely I wait around for seeing something beautiful, and then I adopt the style for GitHub pages. Sometimes this is really easy, and sometimes it isn’t. This particular time it was an interesting task because the functionality of the thing that I wanted to convert was not straight-forward. I first found this interface deployed by the Imperial College London. It was simple, and beautiful! It already had a “Fork me on GitHub” banner, so I figured it was already represented with jekyll. What I found at the link was confusing, because there was a table of metadata:
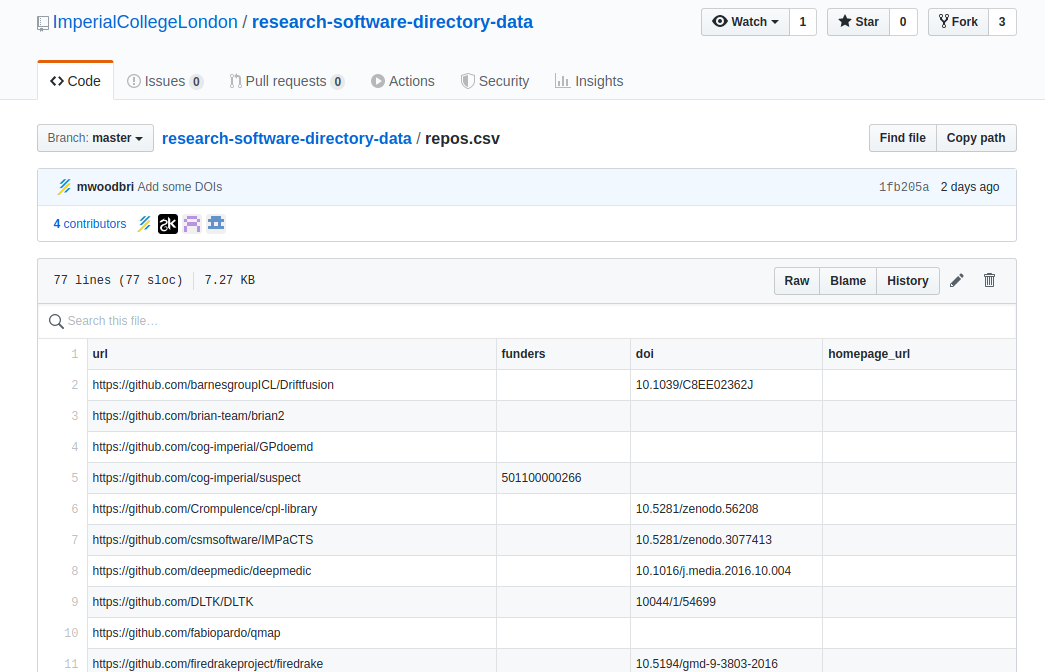
But take a look at the name of the repository - it doesn’t match the one that is deploying the interface,
which should be ImperialCollegeLondon/research-software-directory. I curiously then
navigation to the GitHub repository that I thought should be deploying the site. And I found it!
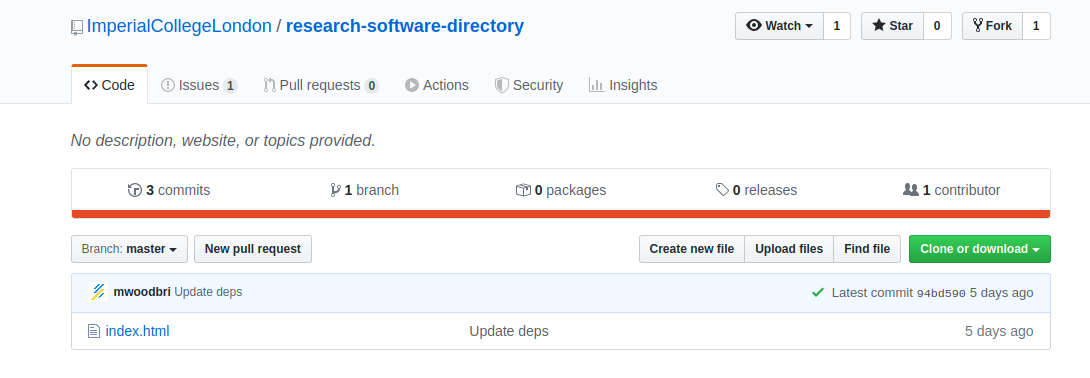
So - I figured that the data was kept in a separate repository, and deployed statically here. Although it wasn’t intuitive, I figured there were design choices to support this structure, and I thought that maybe I could help by creating a single repository that would serve both data and interface.
Alogia
My next part of the investigation was to clone the repository (the index.html above) and then test it locally. I was certain that I would find a reference to the data file. I found where the set of items referenced are looped through:
transformItems: (items) => items.map(item => ({
...item,
topics: item.topics && item.topics.join(', '),
contact_name: item.contact && item.contact.match('(.*) <(.*)>')[1],
contact_email: item.contact && item.contact.match('(.*) <(.*)>')[2],
homepage_url_style: item.homepage_url ? '' : 'display: none',
rsotm_style: item.rsotm ? '' : 'display: none',
updated_at: timeago.format(item.updated_at * 1000),
}))
But the closest I could find to a link to the data file on GitHub was the “fork me on GitHub link”
<a class="github-fork-ribbon"
href="https://github.com/ImperialCollegeLondon/research-software-directory-data/blob/master/repos.csv"
data-ribbon="Fork me on GitHub" title="Fork me on GitHub">Fork me on GitHub</a>
Of course then I started looking through the code, assuming that this div was used to grab and then fetch the URL. I didn’t find it. But then I found this (the key and token are changed):
const searchClient = algoliasearch('BBBBREAD', '01234501234501234501234512345');
const search = instantsearch({
indexName: 'software_showcase',
searchClient,
});
And it clicked immediately that the web interface was using something called Alogia Search. I checked out the service and created a free account, and indeed, the company provides easy ways to upload data (usually tabular) and then expose via several APIs. This means that the data file was being sent to Alogia first, and then the API keys and application id were referenced to retrieve it. This is where I stepped back and thought of my use case, and the likely user.
Remove Additional Dependencies
It’s important to think about your audience when designing something. This is probably obvious, but I sometimes need to remind myself of it. My audience is the world of GitHub. We want to fork something, and with minimal change (maybe just changing a title and turning on GitHub pages) have it work off the bat. Requiring a user to create an account, add credentials, and then separately update and maintain a data file was too hard. Or maybe it just wasn’t easy enough for what I wanted. Either I needed to give up on the project because it wouldn’t work or I needed to figure out how to extract the interface and combine with native GitHub tooling. I decided to do the latter, and removed all of the JavaScript that references anything with Alogia. But I want to still give a shoutout to this company, because they are making something that is typically very hard for groups (search) much easier.
How does it work?
Listing
Instead of using Alogia and the associated javascript, I figured out how to parse GitHub pages public repositories metadata, and then generate into the “ais-Hits-item” div, the logic that you can see here.
Search
The sidebar checkboxes and top box that drive the search are handled differently. For the checkboxes, I decided that the terms for licenses and languages afforded well to classes, so I simply added a class for each to each link. This means that, for example, whenever there is a change to a checkbox event (meaning a box is checked or unchecked) I can hide all the checkboxes, and then show any of those that have one or more of the selected classes. If the user has no boxes checked, this indicates that we should show everything. That looks like this:
$('.ais-RefinementList-checkbox').change(function() {
// Get all checked boxes
var checkedVals = $('.ais-RefinementList-checkbox:checkbox:checked').map(function() {
return "." + this.value;
}).get();
// If nothing checked, just show them all
if (checkedVals.length == 0) {
var selected = $(".ais-Hits-item");
} else {
// Filter elements on page
var repos = $(".ais-Hits-item");
repos.hide();
// Only show those belonging to class
var classes = checkedVals.join(", ");
var selected = $(classes);
}
// Show those selected, update those found
selected.show();
$("#selected-count").text(selected.length);
});
I don’t use JavaScript a lot, so I tend to add a lot of comments to ensure that future me knows what’s going on. Actually (what am I saying!) I do this for all my code, because I have the memory of a goldish. For the search input, I took an approach of adding some of the metadata to data attributes of each link, and then I could use those attributes to search based on a query. If we use the “change” event then we’d only trigger when the box loses focus (after you type and move your cursor away) however I wanted to change dynamically, so I did it on the “input” event.
$(".ais-SearchBox-input").on("input", function(e) {
var input = $(this);
var query = input.val().toLowerCase();
// Only update if different
if (input.data("lastval") != query) {
input.data("lastval", query);
// Hide those without term
repos.show().filter(function() {
text = ($(this).attr("data-description") + " " +
$(this).attr("data-language") + " " +
$(this).attr("data-license"));
text = text.replace(/\s+/g, ' ');
return !text.toLowerCase().includes(query);
}).hide();
}
});
I have an inordinate number of public repositories (over 500!) so I view my user account as an extreme case for the search. It’s not as speedy as the smaller example that I derived it from, but given the size and my quick “make it work” JavaScript, I think it’s a good first shot.
Updates
I was sometimes annoyed about needing to scroll back to the top, so I enchanged it with a “scroll to top” bottom in the bottom right. You can also edit the color of this button easily in the “_config.yml”:
# Scrolltop color
scrolltop_color: "#fd1268"
If you want to further customize the interface, you can update the style or
script files to your liking. If you have a question, requested change, or
want to contribute, please open an issue!
I’m happy to help. For example, let’s say that like the ImperialCollegeLondon
you wanted a custom data file to populate the fields here. That would be relatively easy to update the template here to do!
You’d want to edit the loop in pages/index.md to loop through entries
in an associated data file, and write whatever metadata you want to each box.
Don’t forget to update the feed.xml
that also renders from the same source. The search (both sidebar and text) can be easily modified based on the classes
(currently languages and licenses) and the description. Please ask if you’d like some
help with this - we can develop another template for others to use.
Thanks for stopping by!
Suggested Citation:
Sochat, Vanessa. "GitHub Code Search." @vsoch (blog), 01 Mar 2020, https://vsoch.github.io/2020/github-search/ (accessed 14 Jul 26).