How chonky are your repositories and files on GitHub? I have almost 600 repositories at this point, and I was genuinely curious. Could I put together a quick interface to find the chonkiest of the chonks across my GitHub code? Yes!
The Chonker Awards
In my most ridiculous project yet, I present to you, the Chonker Awards!
Yes, this is yet another itch that I wanted to scratch, and I decided to have some fun with a little bit of time on my last day. It’s exactly as terrible as you might guess.
How does it work?
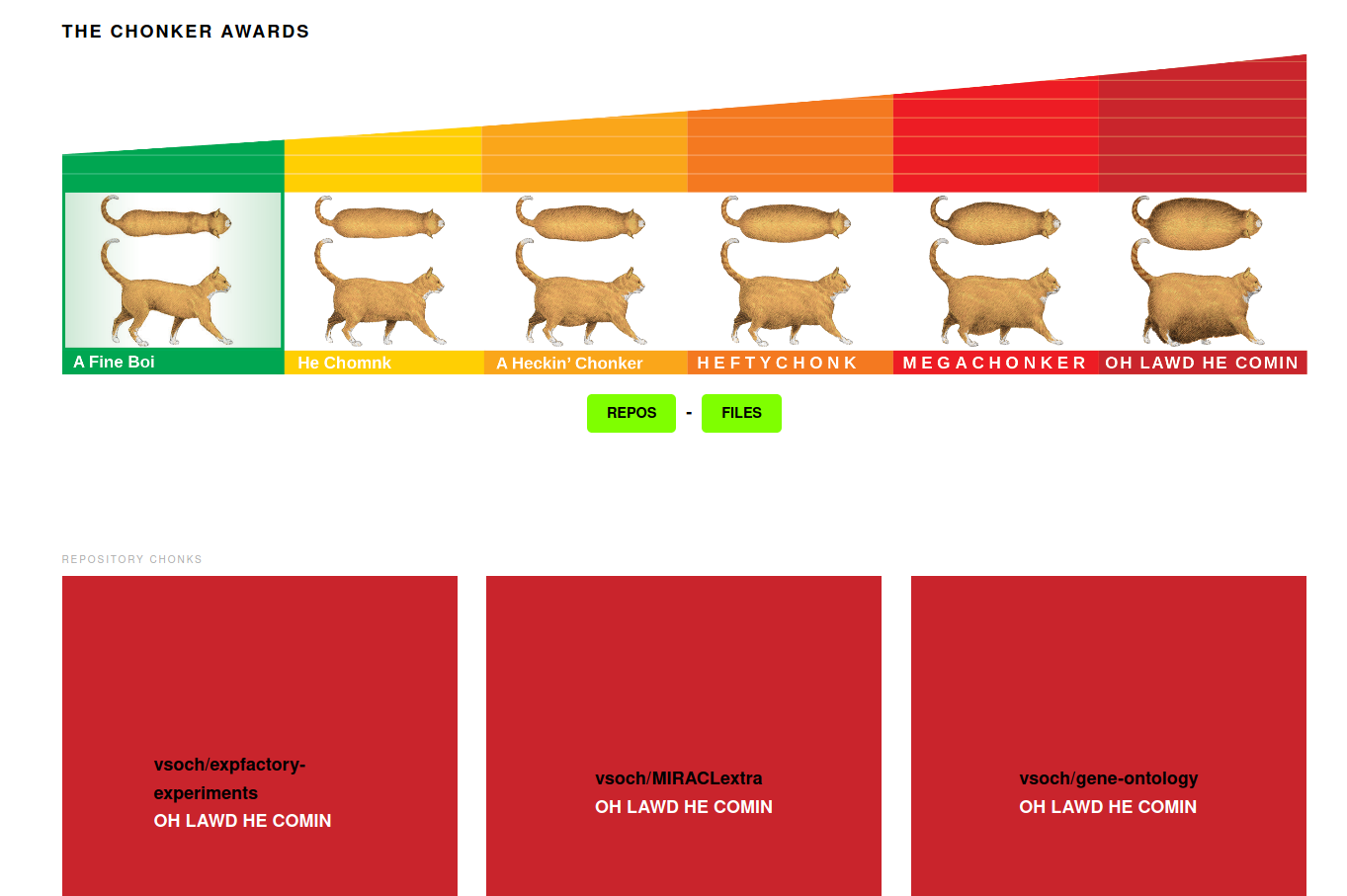
For each of repositories and files, I use the GitHub API to look for the largest of each. This means using the repository API for listing repos, and code search to find files associated with my user. For the first, it’s fairly easy to do a paginated set of requests to just get all repos and sort them by size, but for the second we need to employ a strategy of finding an upper limit, and then slowly decreasing it with searches until we hit a desired total. Since I wanted to assign 10 awards for each level of Chonk, I ultimately would have 60 results for each of files and repos. As you scroll down the page, the level of chonk is updated with different label and colors. Here we see the whole gamut, 10 of each for 6 colors for one category!

What did I learn?
It’s interesting to look at the top sizes, for each of repos and files.
Repositories
Not surprisingly, the first result is a mono-repository for web based experiments, my fork of the Experiment Factory experiments repository. This single repo has more than 100 experiments, including not just scripts, but also a lot of images. I suspect they aren’t all optimized, making the repository 3382.86 MB (3.3 GB). This still, however, is quite a bit less than the maximum repository size of 10GB. But it does hint that this stratgy of storing all your stuff in one place might not scale well. For the experiment factory, if there ever needed to be, say, 500 to a thousand experiments, it would be too big. It would also be really annoying to clone!
The next repository (number 2!) was not surprisingly a repo that exists solely to provide data, a project called MIRACLextra that I helped out with a few years ago. The third was a bit surprising, because at face value it looked like a pathetic little interface. But when I looked closer, the images folder was filled with huge image files! The next repos in the Chonker Awards were similar in that they were documentation or blog sites, but likely have chonked up in size due to image files. It might be time to start looking at some of these image optimization services! You can browse further if you like. The strongest takeaway is that what tends to scale our repos are images and data. I’m not greatly surprised by this.
Files
Looking at files can be interesting because they can be hiding everywhere! My largest two files were flash (.swf and .exe) files that I made when I was a young kid (not sure they can play anymore) reading a poem. The third is a saved machine learning model for a bot that I trained on my Mom’s GitHub posts (I know, I’m terrible, but I think she liked it!). The next set of files were an R data (.Rda file), a video, and then gifs. We then moved into brain maps, more flash, and compressed archives. No surprises here!
How can I use it?
If you want to create your own Chonker Awards for your GitHub user, you can head over to the GitHub repository and use it as a template (or fork, depending on your preference). You’ll want to run find-chonkers.py with your GitHub username, ideally after exporting a token:
export GITHUB_TOKEN=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
python find-chonkers.py <username>
And this will update the data in the _data folder. Note that you’ll likely want to update the min size and test different queries to find an appropriate upper limit, and size to decrement by for the code search. If you decide to use the GitHub action, you’ll also want to ensure that your username is properly represented.
What should I care?
You probably shouldn’t, this project was entirely for fun, to celebrate my last day at Stanford, and I hope that you enjoyed it!
Suggested Citation:
Sochat, Vanessa. "The Chonker Awards." @vsoch (blog), 29 Jan 2021, https://vsoch.github.io/2021/the-chonker-awards/ (accessed 14 Jul 26).