Wow, this is the first post of the year - at the end of February! Dear reader, I haven’t written as much because I’ve been much more fully invested in my work. I’m on cloud nine working on Flux Framework and just recently my talk that introduces the Flux Operator was accepted for Kubecon 2023 in Amsterdam!. This might be the last time they accept a remote co-speaker so I am infinitely grateful. I’m so proud to be able to present this on behalf of the Flux team. Flux is awesome, as is it its slightly rebellious child, the Flux Operator 😎️ and I hope you get to check them out, or the presentation! I will rock this talk, even if it’s remote!
Operator SDK
Let’s get into business! Yesterday evening I started to look into how to add a Python SDK for my Operator. The reasons are because I want to be able to programmatically bring up an entire persistent MiniCluster, and test the multi-user case (meaning we have multiple accounts). I can’t do this easily with a single YAML CRD because I need to be able to make requests as different users, and easily check output. For the flux-cloud tool we also currently create MiniClusters by way of applying yaml in a bash script, and I’d like to maximally put code in Python, because we’ve hit a few issues with different shell variants on different operator systems. I knew almost immediately that I wanted a Python SDK, not just to make it easier to apply the MiniCluster CRD, but also to make it easy to port forward without needing the kubectl port-forward command. This turned out to be a larger investigation than I had anticipated, and a lot of what I needed to do was not documented. In this post I will describe what I learned and did for hopefully the next person.
History of Generation
Your first instinct is likely to do some searching for “how to generate a Python sdk using the operator-sdk.” It turns out, they used to have this provided natively:
$ operator-sdk generate openapi
(That command does not exist anymore!) and I found a lot of mentions that this was being deprecated, but not any kind of guidance for actually how to do it. The repository for the command is also really sparse. I found a note and the only description for how to replicate it using this tool in a long release note. For historical memory, here is the snippet that was useful:
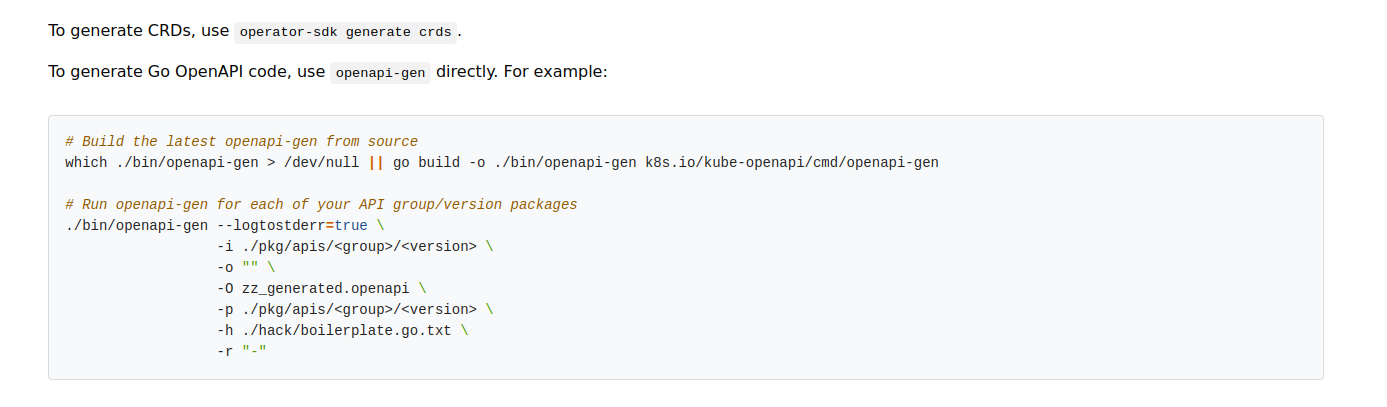
And this entire process was confusing because I kept stumbling on openapi-generator.tech that is needed, but comes at a later step. To step back a bit, the reason we are using openapi is that it is going to allow us to create a structure (in json) that defines our API endpoints (for the Operator interactions with Kubernetes) and then generate our Python SDK. If you’ve heard of Swagger, it’s built around the openapi spec and is going to be part of this process.
Step 1. Build the openapi-gen binary
Okay great. So I made a new section in my Makefile to build the binary from the source code, and run this command (not fully understanding what it would do yet). Note these are just snippets and not the entire Makefile (which you can see here).
OPENAPI_GEN ?= $(LOCALBIN)/openapi-gen
# Build the latest openapi-gen from source
.PHONY: openapi-gen
openapi-gen: $(OPENAPI_GEN) ## Download controller-gen locally if necessary.
$(OPENAPI_GEN): $(LOCALBIN)
which ${OPENAPI_GEN} > /dev/null || (git clone --depth 1 https://github.com/kubernetes/kube-openapi \
/tmp/kube-openapi && cd /tmp/kube-openapi && go build -o ${OPENAPI_GEN} ./cmd/openapi-gen)
In the above, the “openapi-gen” section looks to see if the binary exists in our local bin, and if it doesn’t find it, it does a shallow clone to a temporary directory to build the binary to that location.
Step 2. Generate the Spec
Okay great! So now we just run the binary, akin to how we were shown in the example above, and we get the output, right? Like this:
export API_VERSION=v1alpha1
./bin/openapi-gen --logtostderr=true -i ./api/${API_VERSION}/ -o "" -O zz_generated.openapi -p \
./api/${API_VERSION}/ -h ./hack/boilerplate.go.txt -r "-"
Absolutely wrong! When I ran this, it largely generated an empty Go file “api/v1alpha1/zz_generated.openapi.go” in my api directory (as I asked it to above). I was very disappointed. This is where it got tricky, because I couldn’t find any documentation for how to do this. This is when I became an investigator. My spidey senses were telling me, akin to how kubebuilder uses weird tags inline with code for everything, that I needed to add them. So I started trying stuff. Looking at the mpi-operator as an example, I thought I found the answer with these tags:
// +genclient
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// +kubebuilder:object:root=true
// +kubebuilder:subresource:status
that appeared before different structs. I already had the last two - they came default with the kubebuilder template. However, adding them yielded nothing. So then I started snooping in other files in the folder. I must have been missing something! That was when I found this file. Yes, of course the answer was in a largely empty looking file, where tags could easily be mistaken for part of the license header. This was the file and content I needed to add to that api package:
// +k8s:deepcopy-gen=package
// +k8s:defaulter-gen=TypeMeta
// +k8s:openapi-gen=true
// Package v1alpha1 is the v1alpha1 version of the API.
// +groupName=flux-framework.org
package v1alpha1
Once I added that, the file generated by the command above was chock full of API goodness. At this point, I added this generation logic more explicitly to my Makefile under generate - so whenever I generated a new binary for the operator this would be generated too (it’s fairly quick):
API_VERSION ?= v1alpha1
.PHONY: generate
generate: controller-gen openapi-gen
$(CONTROLLER_GEN) object:headerFile="hack/boilerplate.go.txt" paths="./..."
${OPENAPI_GEN} --logtostderr=true -i ./api/${API_VERSION}/ -o "" -O zz_generated.openapi \
-p ./api/${API_VERSION}/ -h ./hack/boilerplate.go.txt -r "-"
Step 3. Cleaning up models
The above generated two kinds of API rule violations (in bulk). The first was called a “names_match.” Here is an example (not from the Flux Operator):
API rule violation: names_match,./testdata/listtype,AtomicList,Field
After some digging I found that for the custom resource definition, I had been naming things wrong. Kubernetes wants to see Struct names that correspond to their json names. As an example, if I have a json name of “class” (as I did under a MiniClusterVolume spec) I couldn’t call the struct a “StorageClass.” They needed to coincide. A fix for this would look like the following:
- StorageClass string `json:"class"` // incorrect
+ Class string `json:"class"` // correct
I could have also changed the json field to “storageClass” but I would rather not change the user interface. I needed to do this easily across 10+ different fields. The other error I saw looked like this:
API rule violation: list_type_missing
Also for a specific struct. I found the answer here and was able to do a fix by specifying the list type for every kind of list in my spec. As an example:
// +listType=set
Ports []int32 `json:"ports"`
After those fixes, all of the warnings went away and I could move forward.
Step 4. Generate a swagger.json
At this point I fumbled for a while. I knew that I had the openapi spec for the operator dumped into Go. Next I needed to somehow translate that into Python. I suspected the intermediate step would be writing it into a swagger json spec. Thankfully, a few projects have done this before, so I found many examples for using spec.Swagger to do exactly that. The reason I couldn’t mimic their approaches exactly was because I was using the operator-sdk, and I think there is a slightly different approach using “the other operator development kit” that I haven’t tried yet! Not knowing what I was doing, I just ran that script to again see what would happen. The first time failed because it required an API version, so I added that:
$ go run hack/python-sdk/main.go v1alpha1
A ton of json was output to the terminal. This is good! I saw that most projects were saving this to a swagger.json file alongside the Go variant, so I added a section to my Makefile to do that too:
.PHONY: api
API_VERSION ?= v1alpha1
SWAGGER_API_JSON ?= ./api/${API_VERSION}/swagger.json
api: generate api
go run hack/python-sdk/main.go ${API_VERSION} > ${SWAGGER_API_JSON}
Step 5. Generate your SDK!
We were close! At this point I knew I could convert that json into an SDK.
Install the generator binary
I went to this page and chose an install method, and added it to my Makefile. It is literally just a wget of the binary.
SWAGGER_JAR ?= ${LOCALBIN}/openapi-generator-cli.jar
.PHONY: swagger-jar
swagger-jar: $(SWAGGER_JAR) ## Download controller-gen locally if necessary.
$(SWAGGER_JAR): $(LOCALBIN)
wget -qO ${SWAGGER_JAR} "https://repo1.maven.org/maven2/org/openapitools..."
As I write this I am questioning my choice of Java, but that seems to be what many others chose too, so I’m good with it for now. Once I had this, I updated my api generation block to use it, per instructions in the documentation and other examples I had seen. The first thing I tried:
export API_VERSION=v1alpha1
export SWAGGER_JAR=./bin/openapi-generator-cli.jar
export SWAGGER_API_JSON=./api/${API_VERSION}/swagger.json
java -jar ${SWAGGER_JAR} generate -i ${SWAGGER_API_JSON} -g python -o ./sdk/python/${API_VERSION}
That didn’t actually work. It was missing a config file!
Create a swagger_config.json
I found an example with the mpi-operator, and customized it for the Flux Operator
java -jar ${SWAGGER_JAR} generate -i ${SWAGGER_API_JSON} -g python -o ./sdk/python/${API_VERSION} \
-c ./hack/python-sdk/swagger_config.json
of course not knowing what most of the logic was describing. That actually did it, and next was magic. ✨️ The first time that I saw a Python module generated from nothing, I was through the moon. We were almost there!
I shared this on a (now quiet) slack with some of my colleagues, where I then immediately regret it. I can only imagine how annoying it is for someone to post something at 7:30pm on a Friday.
Vanessa, please go off and do something that indicates you have a life.
I doubt anyone would actually say or think that, but as we all know, we tend to think the worst.
Vanessa, you are a goblin that is going to die alone with your computer.
Stop that, internal self-deprecation voice! In my own defense of this hypothetical jab, this Hidden Brain episode mentioned a study that suggests that we are happiest when we aren’t aware of ourselves. When I’m programming on a Friday evening with music streaming, probably surrounded by blue and purple lights walking on my treadmill desk, that’s usually the kind of flow I have. Aside from running and working would I like to have different experiences that give me joy? Of course. But largely (and especially in a pandemic) that is outside of my control. I digress! What I did next is inspect the generated content, and found ways to customize the template using command line flags or editing the “swagger_config.json.” The final command looked like this:
java -jar ${SWAGGER_JAR} generate -i ${SWAGGER_API_JSON} -g python-legacy -o ./sdk/python/${API_VERSION} \
-c ./hack/python-sdk/swagger_config.json --git-repo-id flux-operator --git-user-id flux-framework
Note that “python” is switched to “python-legacy” - we will unwrap that a bit more in the next sections.
Debugging missing imports
I then tried making a simple example to import and instantiate classes, and then apply the custom resource definition to a running MiniKube cluster. I got an error about missing this import:
fluxoperator.model.v1_object_meta.V1ObjectMeta
Hmm, this was something that my custom resource definition doesn’t define natively, but it’s part of the Kubernetes API. I had thought based on looking at my swagger_config.json this would be substituted for me. To step back, in our swagger_config.json there was a section called “importMappings” that (I think?) was supposed to allow substitution of a particular field in the swagger.json to a different import. E.g.,
{
"packageName" : "fluxoperator",
"projectName" : "flux-framework",
"packageVersion": "0.0.0",
"packageUrl": "https://github.com/flux-framework/flux-operator/tree/main/python-sdk/v1alpha1",
"importMappings": {
"V1ObjectMeta": "from kubernetes.client import V1ObjectMeta",
"V1ListMeta": "from kubernetes.client import V1ListMeta"
}
}
In the above, it should have been the case that V1ObjectMeta was derived from that import. But it wasn’t happening. It was trying to import a module in my generated code that didn’t exist. This is when I posted this tweet. And note it is many hours later since getting the original thing to generate. I had finally had dinner and then continued to experiment, to no avail. I don’t like asking for help until I feel like I’ve exhausted my ideas. Yes I am very stubborn. But I also regret that, because I had two ideas after posting it. But then I was really sleepy, and kind of wanted to turn into a pumpkin 🎃️. So I turned off my computer, climbed under my weighted blanket (by the way, I recently invested in a heating pad that automatically shuts off and it’s amazing for cold nights next to a window when it’s -6 outside) snuggled with my heating pad, and went off into dinosaur dream land. End scene!
Fixing Missing Imports
Setting - this morning. Action! I woke up this morning and wanted to test out my ideas. What was the first one?
Let there be a module!
My theory was that I could just create the missing modules, where in the files they import what is expected. E.g., in this file:
fluxoperator/model/v1_object_meta.py
I would just write:
from kubernetes.client import V1ObjectMeta
And instead of allowing a portion of a module I didn’t have to be included in my swagger.json spec, I explicitly wrote rules in my main.go to parse the modules into custom classes that I would define:
// Our strategy here is to replace specific needs with classes we will define
func swaggify(name string) string {
// These are specific to the Flux Operator
name = strings.Replace(name, "github.com/flux-framework/flux-operator/api/v1alpha/", "", -1)
name = strings.Replace(name, "../api/v1alpha1/.", "", -1)
name = strings.Replace(name, "./api/v1alpha1/.", "", -1)
// k8s.io/apimachinery/pkg/apis/meta/v1.Condition -> v1Condition
name = strings.Replace(name, "k8s.io/apimachinery/pkg/apis/meta/v1.Condition", "v1Condition", -1)
// k8s.io/apimachinery/pkg/apis/meta/v1.ListMeta
name = strings.Replace(name, "k8s.io/apimachinery/pkg/apis/meta/v1.ListMeta", "v1ListMeta", -1)
// k8s.io/apimachinery/pkg/util/intstr.IntOrString -> IntOrString
name = strings.Replace(name, "k8s.io/apimachinery/pkg/util/intstr.", "", -1)
// k8s.io/apimachinery/pkg/apis/meta/v1.ObjectMeta
name = strings.Replace(name, "k8s.io/apimachinery/pkg/apis/meta/v1.ObjectMeta", "v1ObjectMeta", -1)
return name
}
It’s a bit of a hard coded approach, but I thought it could work. And it did! The above would generate a flattened definition of “V1ObjectMeta” that I could define as a custom import in the swagger_config.json. Using the “python-legacy” generator I was able to do the imports:
from kubernetes import client, config
from fluxoperator.models import MiniCluster
from fluxoperator.models import MiniClusterSpec
from fluxoperator.models import MiniClusterContainer
from fluxoperator.model.v1_object_meta import V1ObjectMeta
But that’s where my luck ended. You see, when I tried to actually create the MiniCluster or spec, I started getting errors about missing fields (that are defaults). This is where we go back to the “python” vs “python-legacy” specification. I realized that this particular “python” version was being pedantic, it shouldn’t be the case I have to define every field (including those that are optional). My suspicion is that this generator isn’t picking up the kubebuilder flags for optional or defaults. At this point (also after noticing other libraries were using python-legacy) I switched back to that. The list of generators can be seen here. The “you must specify every field!” error went away. This next block of code worked:
# Here is our main container
container = MiniClusterContainer(
cores = 2,
image = "ghcr.io/rse-ops/lammps:flux-sched-focal-v0.24.0",
working_dir = "/home/flux/examples/reaxff/HNS",
command = "lmp -v x 2 -v y 2 -v z 2 -in in.reaxc.hns -nocite",
run_flux=True
)
# There is currently a bug where the defaults are not set/correct, so for example,
# we need to set the deadline seconds or the minicluster will not create.
minicluster = MiniCluster(
kind="MiniCluster",
api_version="flux-framework.org/v1alpha1",
metadata=V1ObjectMeta(
name="lammps",
namespace="flux-operator",
),
spec=MiniClusterSpec(
size=4,
tasks=2,
deadline_seconds=31500000,
containers = [container]
)
)
I also noticed that with “python-legacy” the double module folders (e.g., model and models) went away, and instead of trying to import these extra classes that didn’t exist, they were specified as strings (and I suspect substituted with the logic I provided). At this point I moved forward to create the CRD:
# Make sure your cluster or minikube is running
# and the operator is installed
config.load_kube_config()
crd_api = client.CustomObjectsApi()
# Note that you might want to do this first for minikube
# minikube ssh docker pull ghcr.io/rse-ops/lammps:flux-sched-focal-v0.24.0
result = crd_api.create_namespaced_custom_object(
group="flux-framework.org",
version="v1alpha1",
namespace="flux-operator",
plural="miniclusters",
body=minicluster
)
I lost my mind again with excitement 😹️ when I saw the operator logs jump to life showing (as expected) a MiniCluster being generated! We had just done that from Python! But then I hit a bug again. The certificate generator pod completed, but there was no job. At this point, the debugging strategy I used was to compare a working MiniCluster crd (in json) to the one that was in the “result” variable above. E.g., after applying an equivalent “minicluster.yaml” to run lammps (this one) I could do:
$ kubectl get minicluster -n flux-operator -o json
And what I almost immediately noticed is that the default “deadlineSeconds” was set to 0 in the Python generated one. This was another example (even for the python-legacy version) that a default was not sticking. The defaults were unset in both the swagger.json and the Go generated file, so I concluded this was an issue with the original command to generate the Go spec. I decided that since I could get around this in the meantime by supplying the value, instead of trying to 100% solve it by myself I’d open an issue instead (just now, actually). Once the default was set, and I specified the container to be the Flux runner with “run_flux” set to true to be extra sure, I saw the entire job run, generate the correct output and complete. The final example is here and the final Makefile for this api generation looks like this:
.PHONY: api
api: generate api
go run hack/python-sdk/main.go ${API_VERSION} > ${SWAGGER_API_JSON}
rm -rf ./sdk/python/${API_VERSION}/fluxoperator/model/*
java -jar ${SWAGGER_JAR} generate -i ${SWAGGER_API_JSON} -g python-legacy -o ./sdk/python/${API_VERSION} \
-c ./hack/python-sdk/swagger_config.json --git-repo-id flux-operator --git-user-id flux-framework
cp ./hack/python-sdk/template/* ./sdk/python/${API_VERSION}/
The last line to copy files into the generated directory is for a few setup.py and other README templates that I don’t want to get over-written on a new generation. The general rule seems to be that any existing file will be re-written, but you can add new files and they won’t be (e.g., I added a docs/README.md for the main docs).
Step 6. Document all the things!
At this point although I wanted to do more examples and add functionality to the Python SDK, I realized this was good start, and I decided to add a new Submit Jobs tutorial section that mentions the Python SDK.
Summary
This was a fun learning experience, because I was able to figure out the interaction of (what at the onset felt like) many different components and languages into a holistic pipeline. I’m surprised there aren’t guides out there to describe doing this, or even documentation alongside some of these projects. In this kind of environment, the main strategies I use are to try many things, try to look at source code or (if they exist) any other projects that mention the tool, and as a last resort, asking for help. When I’m out of ideas, often if I just take a break - even just lying down and closing my eyes and letting your mind wander or going for a run - insights or ideas to try can pop up. Sleeping is really great for that too. But it does require a lot of stubborn-ness, and likely patience paired with that. I checked my browser history from yesterday, and starting in the evening when I was working on this, there were 284 unique tabs opened as I searched the internet looking for answers. Is that what software engineers are - professional Googlers? Ha, maybe! I’m OK with that - perhaps the superpower is just having the patience to do that, and knowing how to take a huge amount of information and consolidate it into a next step.
Anyway, if I’m able to figure it out, even if it’s imperfect (e.g., the defaults thing is still a bug here) I still like to share. I’m sure this small guide will be defunct by a year from now, but I hope this can at least give someone in the future some insights. To summarize the process:
- We start with an operator-sdk API definition in Go files
- "+k8s:openapi-gen=true" and similar tags are needed to generate Go Swagger
- The openapi-gen tool turns your Go types files into a single Go file with a spec
- Make sure to fix the API validation errors from that tool
- You then use a small Go script to write that into a swagger Json
- Do a print of the names, and any that are from external libraries, name to something else
- Prepare a swagger_config.json with metadata and these "something else" imports
- Inspect the generated Python SDK, and either copy over or add files that won't be written over
- Write a dummy test example to check that everything works
Okay - more work to do on other things! Thanks for reading!
Suggested Citation:
Sochat, Vanessa. "Python SDK Generator for the Operator SDK." @vsoch (blog), 25 Feb 2023, https://vsoch.github.io/2023/operator-sdk-python-sdk/ (accessed 14 Jul 26).