What happens when a graph database car crashes into a relational database car? You get neo4-django, of course! TLDR: you can export cool things like this from a Django application:
I’ve been working on the start of version 2.0 of the Cognitive Atlas, and the process has been a little bit like stripping a car, and installing a completely new engine while maintaining the brand and look of the site. I started with pages that looked like this:
meaning that fixing up this site comes down to inferring the back end functionality from this mix of Javascript / HTML and styling, and turning them into Django templates working with views that have equivalent functionality.
Neo For What?
Neo4J is a trendy graph database that emerged in 2007, but I didn’t really hear about it until 2014 or 2015 when I played around with it to visualize the nidm data model, a view of the Cognitive Atlas and of the NIF ontology (which seems like it was too big to render in a gist). It’s implemented in Java, and what makes it a “graph” database is the fact that it stores nodes and relationships. This is a much different model than traditional relational databases, which work with things in tables. There are pros and cons of each, however for a relatively small graph that warrants basic similarity metrics, graph visualizations, and need for an API, I thought Neo4j was a good use case. Now let’s talk about how I got it to work with Django.
Django Relational Models
Django is based on the idea of models. A model is a class of objects directly linked to objects in the relational database, so if I want to keep track of my pet marshmallows, I might make a django application called “marshdb” and I can do something like the following:
from django.db import models
class Marshmallow(models.Model):
is_toasted = models.BooleanField(default=True)
name = models.CharField(max_length=30)
and then I can search, query, and interact with my marshmallow database with very intuitive functionality:
from marshdb.models import Marshmallow
# All the marshmallows!
nomnom = Marshmallow.objects.all()
# Find me the toasted ones
toasted_mallows = Marshmallow.objects.filter(is_toasted=True)
# How many pet marshmallows do I have?
marshmallow_count = Marshmallow.objects.count()
# Find Larry
larry = Marshmallow.objects.get(name="Larry")
Neo4Django?
Django is fantastic - it makes it possible to create an entire site and database backend, along with whatever plugins you might want, in even the span of a weekend! My first task was how to integrate a completely different kind of database into a relational infrastructure. Django provides ample detail on how to instantiate your own models, but it’s not a trivial thing to integrate a completely different kind of database. I found neo4django, but it wasn’t updated for newer versions of Django, and it didn’t seem to be taking a clean and simple approach to integrating Neo4j. Instead, I decided to come up with my own solution.
Step 1: Dockerize!
Deployment and development is much easier with Docker, period. Need neo4j run via Docker? Kenny Bastani (holy cow he’s just in San Mateo! I could throw a rock at him!) has a solution for that! Basically, I bring in the neo4j container:
graphdb:
image: kbastani/docker-neo4j:latest
ports:
- "7474:7474"
- "1337:1337"
links:
- mazerunner
- hdfs
and then link it to a docker image that is running the Django application:
uwsgi:
image: vanessa/cogat-docker
command: /code/uwsgi.sh
restart: always
volumes:
- .:/code
- /var/www/static
links:
- postgres
- graphdb
You can look at the complete docker-compose file, and Kenny’s post on the mazerunner integration for integrating graph analytics with Apache Spark.
This isn’t actually the interesting part, however. The fun and interesting bit is getting something that looks like a Django model for the user to interact with that entirely isn’t :).
Step 2: The Query Module
As I said previously, I wanted this to be really simple. I created a Node class that includes the same basic functions as a traditional Django model (get, all, filter, etc.), and added a few new ones:
def link(self,uid,endnode_id,relation_type,endnode_type=None,properties=None):
'''link will create a new link (relation) from a uid to a relation, first confirming
that the relation is valid for the node
:param uid: the unique identifier for the source node
:param endnode_id: the unique identifier for the end node
:param relation_type: the relation type
:param endnode_type: the type of the second node. If not specified, assumed to be same as startnode
:param properties: properties to add to the relation
'''
… blarg blarg blarg
def cypher(self,uid,lookup=None,return_lookup=False):
'''cypher returns a data structure with nodes and relations for an object to generate a gist with cypher
:param uid: the node unique id to look up
:param lookup: an optional lookup dictionary to append to
:param return_lookup: if true, returns a lookup with nodes and relations that are added to the graph
'''
base = self.get(uid)[0]
and then I might instantiate it like this for the “Concept” node:
class Concept(Node):
def __init__(self):
self.name = "concept"
self.fields = ["id","name","definition"]
self.relations = ["PARTOF","KINDOF","MEASUREDBY"]
self.color = "#3C7263" # sea green
and you can see that generally, I just need to define the fields, relations, and name of the node in the graph database to get it working. Advanced functionality that might be needed for specific node types can be implemented for those particular classes.
Functionality for any node in the graph can be added to the “Node” class. The function “link” for example, will generate a relationship between an object and some other node, and “cypher” will produce node and link objects that can be rendered immediately into a neo4j gist. This is where I see the intersection of Django and Neo4j - adding graph functions to their standard model. Now how to visualize the graph? I like developing my own visualizations, and made a general, searchable graph run by the application across all node types:
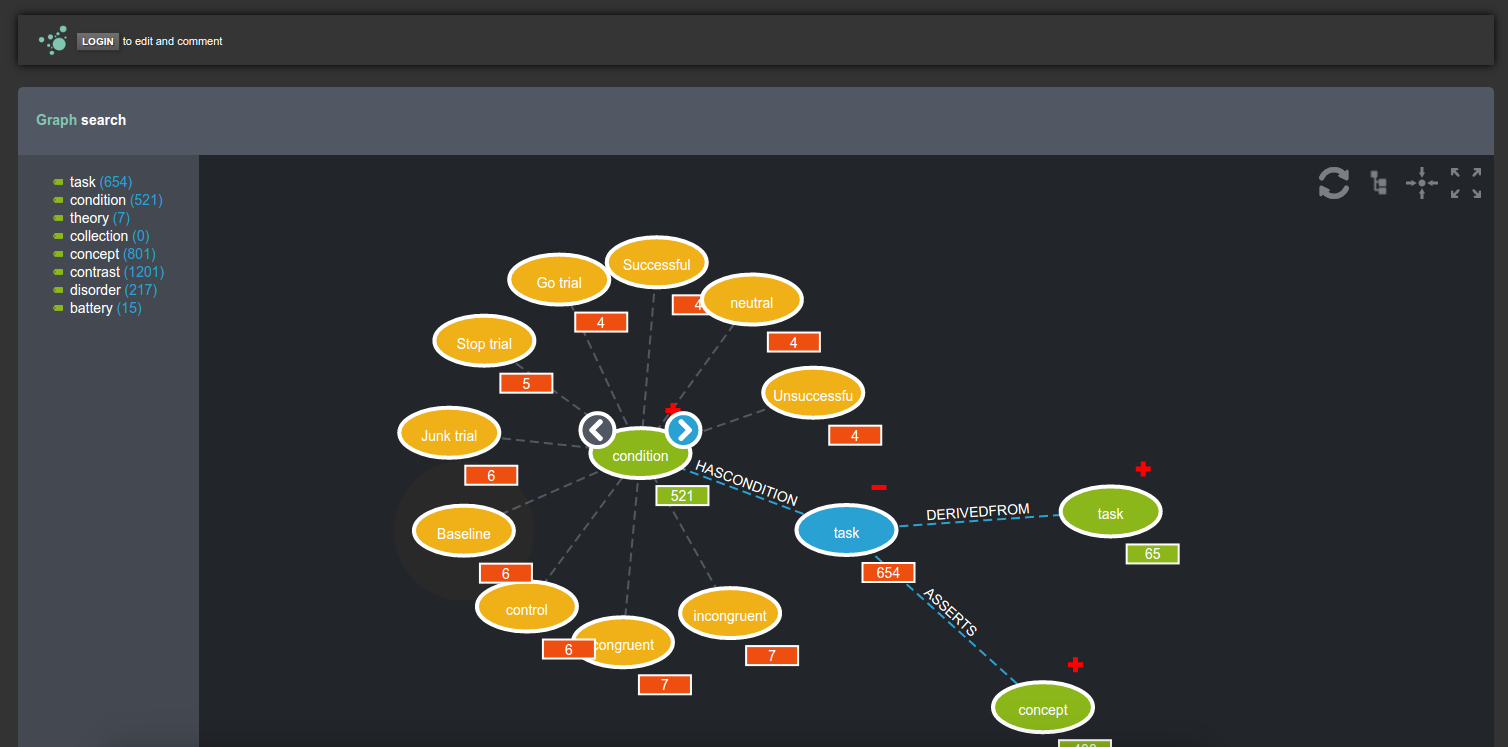
However I realized that a user is going to want more power than that to query, make custom views, and further, share them. The makers of Neo4j were smart, and realized that people might want to share snippets of code as github gists to make what they call a graph gist. I figured why not generate a URL to render this cypher code that can then immediately be rendered into a preview, and then optionally exported and saved by the user? The awesome part of this is that it sends the computing of the graph part off of the Cognitive Atlas server, and you can save views of the graph. For example, here is a gist that shows a view of the working memory fMRI task paradigm. If you’re a visual learner, you can learn from looking at the graph itself:
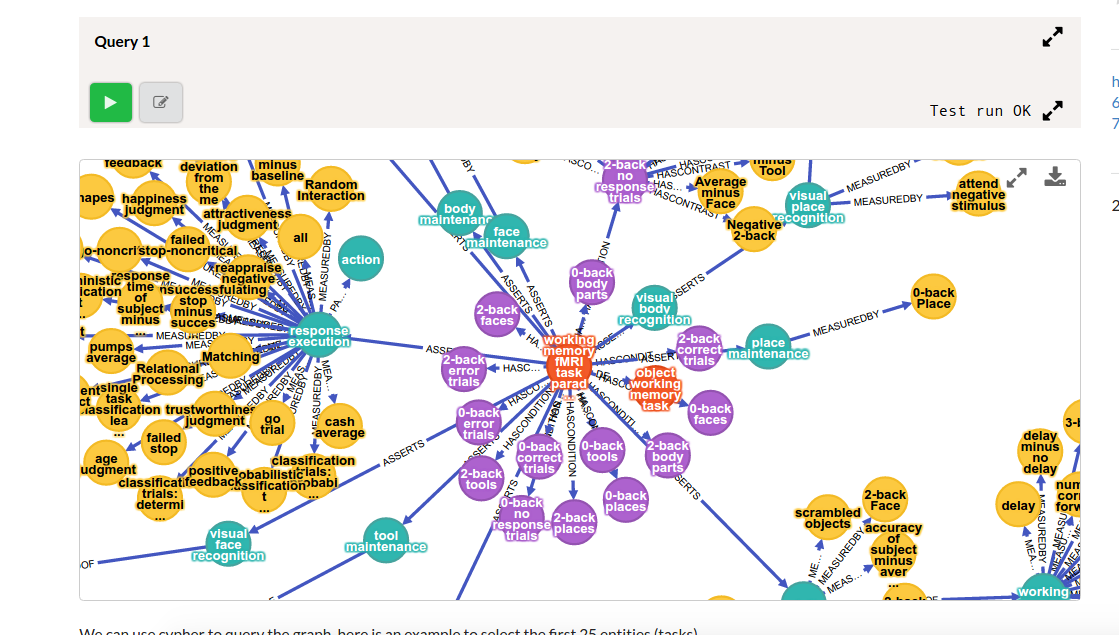
You can see example cypher queries, with results rendered into clean tables:
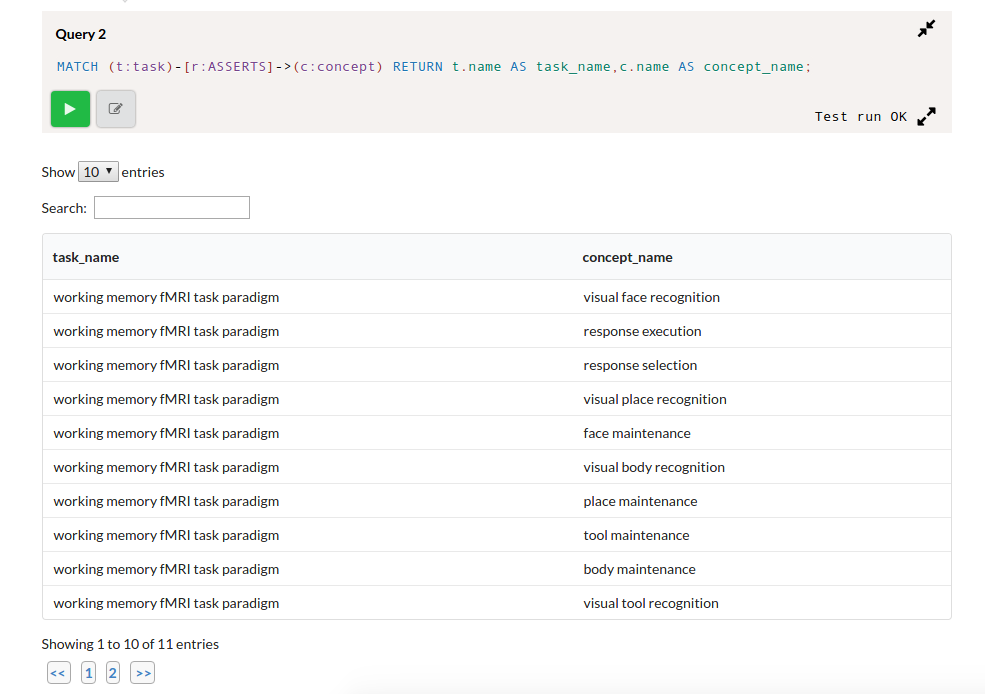
and hey, you can write your own queries against the graph!
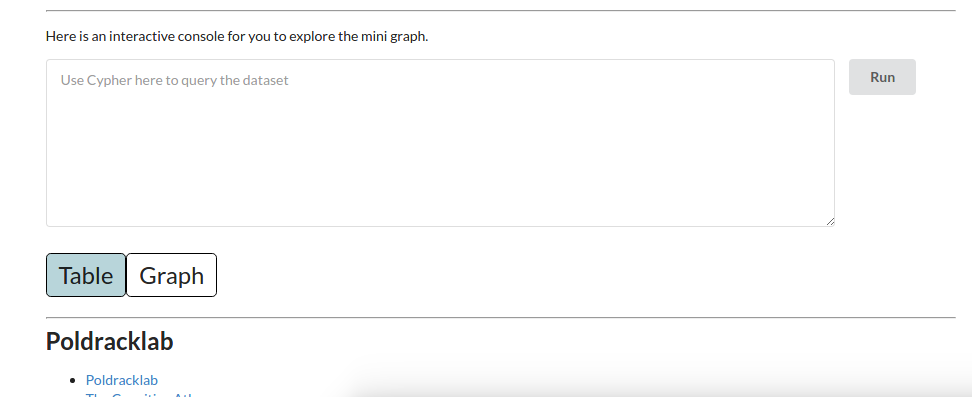
This is a work in progress and it’s not perfect, but I’m optimistic about the direction it’s going in. If more ontologies / graph representations of knowledge were readily explorable, and sharable in this way, the semantic web would be a lot easiest to understand and navigate.
Relational Database Help
Why then should we bother to use a relational database via Django? I chose this strategy because it keeps the model of the Cognitive Atlas separate from any applications deploying or using it. It provides a solid infrastructure for serving a RESTful API:
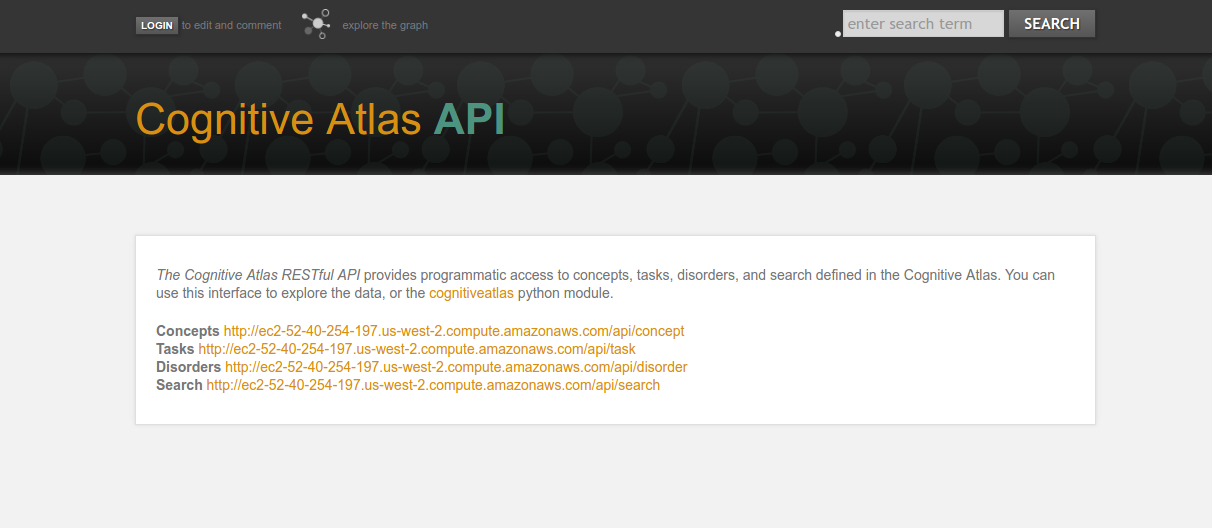
and basic functionalities like storing information about users, and any (potential) future links to automated methods to populate it, etc.
General Thinking about Visualization and Services
This example gets at a general strategy that is useful to consider when building applications, and that is the idea of “outsourcing” some of your analysis or visualization to third parties. In the case of things that just need a web server, you might store code (or text) in a third party service like Github or Dropbox, and use something like Github Pages or another third party to render a site. In the case of things that require computation, you can take advantage of Continuous Integration to do much more than run tests. In this example, we outsourced a bit of computation and visualization. In the case of developing things that are useful for people, I sometimes think it is more useful to build a generic “thing” that can turn some standard data object (eg, some analysis result, data, or text file) and render it into some more programmatic data structure that can plug into (some other tool) that makes it relatable to other individual’s general “things.” I will spend some time in another post to more properly articulate this idea, but the general take away is that as a user you should be clever when you are looking for a certain functionality, and as a developer you should aim to provide general functions that have wide applicability.
Cognitive Atlas 2.0
The new version of the Cognitive Atlas has so far been a fun project I’ve worked on in free time, and I would say you can expect to see cool things develop in the next year or two, even if I’m not the one to push the final changes. In the meantime, I encourage all researchers working with behavioral or cognitive paradigms, perhaps using the Experiment Factory or making an assertion about a brain map capturing a cognitive paradigm in the NeuroVault database, to do this properly by defining paradigms, cognitive concepts in the current version of the Cognitive Atlas. If you have feedback or want to contribute to developing this working example of integrating Neo4j and Django, please jump in. Even a cool idea would be a fantastic contribution. Time to get back to work! Well, let’s just call this “work,” I can’t say I’m doing much more than walking around and smiling like an idiot in this final lap of graduate school. :)

Suggested Citation:
Sochat, Vanessa. "Neo4J and Django Integration." @vsoch (blog), 16 Jun 2016, https://vsoch.github.io/2016/cogat-neo4j/ (accessed 21 Apr 26).