What happens when you combine continuous integration, deep learning, and (traditionally) disparate open source communities? This is a small project I started not even a week ago to help @nsoch that has resulted in a new kind of multi-faceted work. It’s a bit rough around the edges, but I’d like to present the basic concept to inspire your own thinking, and because it’s really cool. Today I want to talk about Open Source Art.

What is OpenSource Art?
While traditionally used for programming, this project combines open source development with community artistic contributions to create the first automated, programmatically generated gallery. It is a fun exercise in using these technologies, but also a bit personal.
Let’s talk about my Mom and I. Since I’ve been maybe twelve years old, we are like pasta water and olive oil. We could barely exist in the same room without pulling out battle axes and World of Warcraft epic gear. I think it’s because we are very different. I am relentless, and stubborn. I value only hard work and transparency, and seek challenge to the point of unrealistic expectations that I forge through sometimes to my own detriment. The way that we conceptualize failure is different. Failure for me is ironiclly both common and elusive, because it happens to me multiple times a day in the traditional sense, but elusive because I rarely conceptualize the state. I can just try again, or try something else, maybe after having some cocoa and working on something else for a while. Failure for my Mom happens more quickly, what I think must be a feeling of being overwhelmed, or not believing that she can do it, or not having the catalyst to start. But we have this common thread, and it’s this propensity to create things. My Mom creates objects and paintings (she is a visual artist). I brute force engineer my way through life. This project is meaningful to me because it made me realize that despite our differences and not understanding one another, we have this common thread. A passion and focus comes directly through our fingers out into the world. I’ll take it!
How do we work together?
Visual arts and open source software development are traditionally (mostly) separate. You occasionally see digital artists that have expertise that spans into data visualization, but let’s think about what the typical gallery or art show looks like. It’s likely the case that you see artist work attributed to one or a few individuals. An artist online portfolio encompasses pictures of their work. The paintings in your favorite gallery are done by one individual, or perhaps a collaboration between a small group. The exception is with groups like the MIT Media Lab that I’ve been taken with since I discovered them, when my friend walked me through a hallway of paper butterflies on the campus. I could have stayed in that magical place forever. When you see this combined beauty in technological and visual design, there is a moment of pause. It’s just so beautiful.
But back to talking about traditional art. You have galleries of things hanging on the wall, or sitting in the middle of a big empty space, and people walking around (mostly) silently and ogling. In my experiences, I’ve walked around silently and pretended to know what was going on. This feels very different from open source, right? Open source (visual) art might be more similar to installation that invite the viewer to “participate.” Still, in these situations it is more the case of
“This is a conceptual work under my name that is exemplifying my creativity by offering this experience to you.”
The generation is commonly not transparent. The artist(s) work behind the scenes and only reveal to you the final masterpiece against the stark white cleanliness of a gallery where it is to be displayed. The underlying process, although it may be mentioned in a small paragraph next to the work or assumed, is mainly hidden as a trade secret or impressive and known skill that the artist does not make directly observable. We are the naive views, and we are meant to gaze, but not know.
Now bring in open source. It’s this powerful, different framework that has many eyes making tiny contributions to develop highly complex things. All steps of development are collaborative, publicly seen, and enduring. In the context of programming, this means that a group of developers opens up their code base for contributions from the community, and many eyes on the code squash the bugs. But can we take it farther? When it gets really, interesting, I would argue, we might combine across people, ideas, and entire disciplines.
How was Open Source Art Made?
The project opensource-art is a dummy example deployed at vsoch.github.io/opensource-art. It combines software engineering, automation, machine learning, and visual art so that many small contributions in both spaces can create unexpected beauty. I got started early with the open source aspect by reaching out to a digital artist that I really like who is behind this beautiful (programmatically generated!) image:

Here is how it works.
We start with an image submission, and actually, smaller or dinkier is usually better because the deep learning container runs faster. Also, if you submit an image 256px or smaller, you get bonus “layer” images generated. Here is a Google Search result I found for “nature”:

We then add a little metadata file to the opensource-art Github repository.. If you read the instructions, I also say it’s okay to send me an email or post an issue, if you aren’t comfortable with Github.
---
layout: work
title: "Avocado Love"
tags: avocados, love, pencil, digital
categories: work
date: 2018-08-14 2:54:46
author: Vanessa Sochat
image: 2018/vanessa-sochat-avocado-love.jpg
---
That’s the only “sorta-programmy” part, because you have to write this text file with a weird syntax (no harsh feelings yaml, I’ve actually taken quite a fondness for you!).
Then you submit a pull request, and it gets tested as a workflow! Don’t get me wrong, writing these workflows is still a messy practice. I suspect I’ll do this over at least 3 or 4 times until I am somewhat happy with it, and tens to hundreds more times over my career. The workflow is a series of steps to build, save things to a cache, get manual approval, and then deploy:
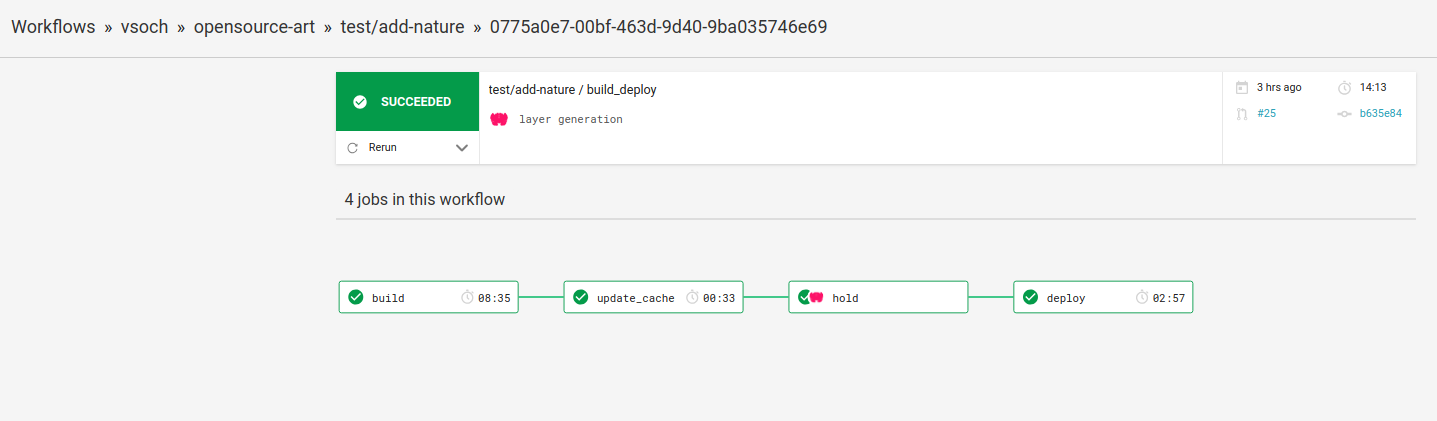
Notice the third little box? That is where I can click on the button, then click to view the artifact files to preview the images, and then click “Approve” to send it webhooking back to finish the workflow. In the build step, this container first uses Google’s deepdream to generate a nice set of image derivations. Here are a bunch:









I’m not hugely interested in the models or algorithms here. I’m optimized to just figure out how it works, and then inject creativity to quickly make some nice variations! But I want to point out that this is another entrypoint for open source collaboration.
The engineer that loves the algorithms can contribute to the algorithm.
And the engineer that loves systems and infrastructure and software can build things using them! And the artist can contribute new textures to flow through those things! With initiatives like this, these separate groups might start talking more to one another, and we make more friends. Everyone wins! We then save them as artifacts so someone can come along and take a look. If a contribution has some element that needs to be fixed or isn’t appropriate, the human eye can catch this. We put it on hold, and then approve it.
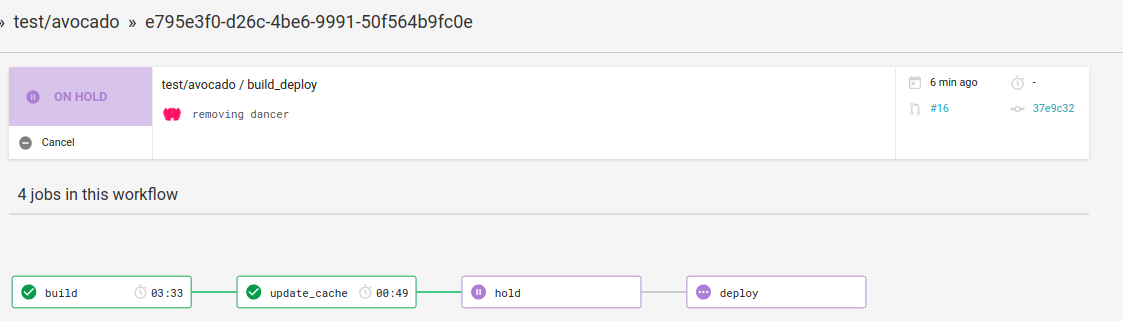
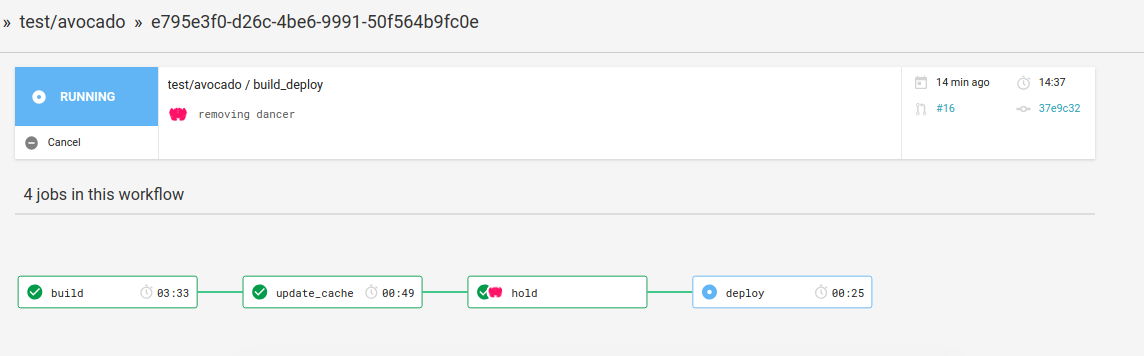
When the merge is done and approved the final “deploy” step has everything rendered live to the gallery. You can see the deployments are linked to commits, and it’s also possible to make manual changes if you are tweaking the design of the site. It won’t hurt anything, because
the gh-pages branch is also used by the builder.
And yeah, that’s mostly it! I can’t claim it’s anything beyond a simple site, but I’m pretty happy with it! The turn around time for this entire thing was less than a week, so I’ll take it!
How can I change it?
Let’s summarize the steps we showed above. We generate an open source gallery, which has contributions from programmers (code bases and testing), visual artists (the textures or graphics), and data scientists (algorithms). That looks like this:
- A graphic and metadata are submit to the repository
- The submission is tested for criteria of interest (image format, size, etc.)
- Continuous integration runs a deep learning algorithm to generate new work and update the gallery
And if we step back, we must realize that the beauty of this setup is how general it is. And how you can replace (or add to!) any of those entire domains or disciplines. How often do you see programmers and chefs working together? What about sound artists?
As a developer I am empowered to dream it, and then make it
Let’s think of all of the steps than can be customized.
The Submission
The submission to the repository can be any kind of media and/or associated content. The metadata, and how it’s validated in the testing step, is completely up to the creator. The submission doesn’t have to be an image - it can be a tabular data file, a sound file, or even a link to an external resource that is used during the testing.
The Testing
The continuous integration testing is just as flexible! Do you want to make a recipe book and test for metadata about an ingredient? Do you want to run a script (or better, a container) that can generate additional content to update a gallery, or a database, or analysis of a data feed and then update your result?
The Build Triggers
Speaking of testing, it’s pretty straight forward that you can have the testing happen when someone submits a change to Github via a pull request. But what if instead you wanted to have a data feed (that is always happily moving along) that has a recent set of records analyzed? You can set up cron jobs on CircleCI to do that. Did you know that you can also trigger the builds with the Circle API? Remember this idea of living data, analyses, and publication? Yeah, we can do that!
The Gallery
In this dummy example, we have an open source gallery of images. It’s cool because you don’t really know exactly what you are going to get from the robots. But the final result of the build that goes back to Github Pages can be any webby thing that you can think of. The generated site might be an API that serves metadata about your submission. It could be a game or contest with an updated leaderboard after running an algorithm (akin to rolling your own Kaggle).
The Container
By the way, there isn’t a dependency on any of the above to just use the container on your own. If you wanted to let people play with your algorithm in advance, just give the command to run the container. Here you go! Here is the avocado image, download it to your computer, and run the container:
wget https://vsoch.github.io/opensource-art/assets/images/2018/vanessa-sochat-avocado-love.jpg
$ docker run -v $PWD:/data vanessa/deepdream:0.0.9 --help
...
DeepDream OpenSource Art
optional arguments:
-h, --help show this help message and exit
--input INPUT image to run deepdream on, recommended < 1024px
--layers save images of intermediate layers
--guide GUIDE second image to guide style of first < 1024px
--models_dir MODELS_DIR
directory with modules (extracted gist zip) folders
--output_dir IMAGE_OUTPUT
directory to write dreams
--input_dir IMAGE_DIR
directory to write dreams
--layer_filter FILTER
if saving --layers, filter based on this string
--frames FRAMES number of frames to iterate through in dream
--scale-coeff S scale coefficient for each frame
$ docker run -v $PWD:/data vanessa/deepdream:0.0.9 --input vanessa-sochat-avocado-love.jpg --layers
Try changing the scale coefficient, and adding an image guide! The image guides (meaning integrating a second image into the style) add a very cool effect.
Contribute!
I hope after reading the above you consider reading more about the project, and consider making a submission. I didn’t go into any of the details of the algorithm, or the workflow, or the circle configuration, because there is too much to put here! But I’d love to chat with you about any of these components If you want to make a submission, here are some tips:
- I’ve found that smaller images (even textures) are more fun
- The image guide (
--guide) argument adds a lot of richness, how can you combine them into the algorithm? - How can we integrate layers? (e.g., if you are running it, look at
net.blobs.keys()) - Can we have the model selection be a variable too? (see this issue)
- If you aren’t great with Github, reach out to me and I’ll help you
If not, I hope that you are inspired to build, create, and dream. :) This general framework has utility beyond visual enjoyment and extends to quality analysis, science, and streaming, living data science.
This post is dedicated to Natacha Villamia Sochat
Suggested Citation:
Sochat, Vanessa. "Open Source Art." @vsoch (blog), 16 Aug 2018, https://vsoch.github.io/2018/opensource-art/ (accessed 14 Jul 26).