Dearest user, how do you build?
It’s great that we can build using Docker Hub or Singularity Hub, but somebody has to pay for it. Singularity Hub gets amazing support from Google, but I’m painfully aware that this can’t last forever. And what if the robots revolt? A user generally doesn’t want to need to set up his or her own infrastructure to constantly serve manifests to find container builds. If this were the case, you could run a Docker Registry or a Singularity Registry Server. However, there’s one thing that I have noticed.
It’s reasonable and affordable to pay for object storage
While it’s likely the case that your lab isn’t running a container registry, I would bet you have some funds invested in Amazon S3 or Google Storage. So, given that:
- GitHub pages can serve (version controlled) websites
- continuous integration services (CircleCI, TravisCI) can serve as builders
- we are willing and able to pay for object storage
Why is a static container registry not a thing? Specifically, GitHub pages can serve a web interface and a static API. The builds can happen using continuous integration. The containers go to object storage. Static container registries need to be a thing!
The Static Registry: an Early Example
This week I’ve put together the first example of what I’m calling a static container registry. It serves the entire web interface and API via GitHub pages, and performs all builds using Continuous Integration (CircleCI). And hey, it looks just like it’s siblings Singularity Hub and Singularity Registry:
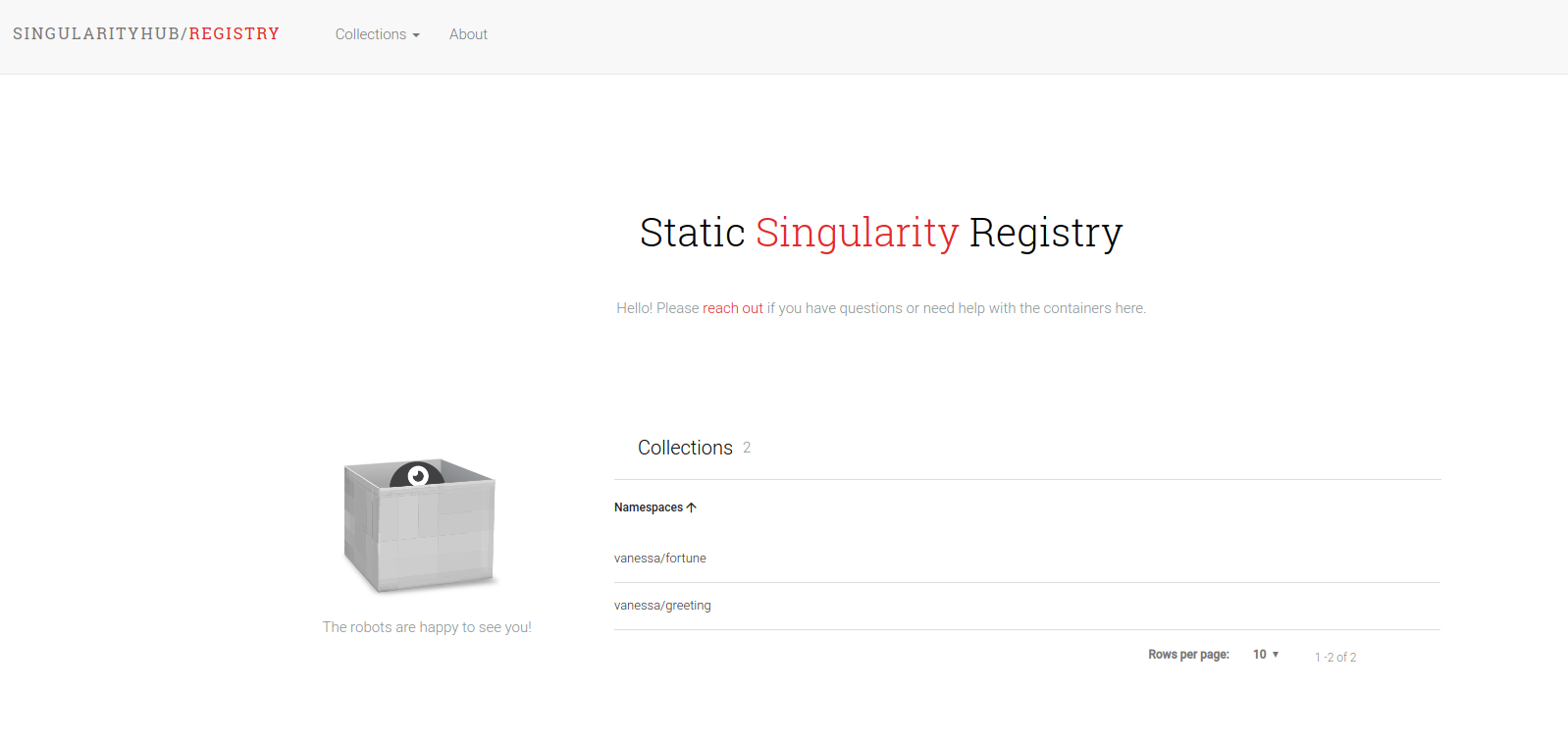
Here is an example collection:
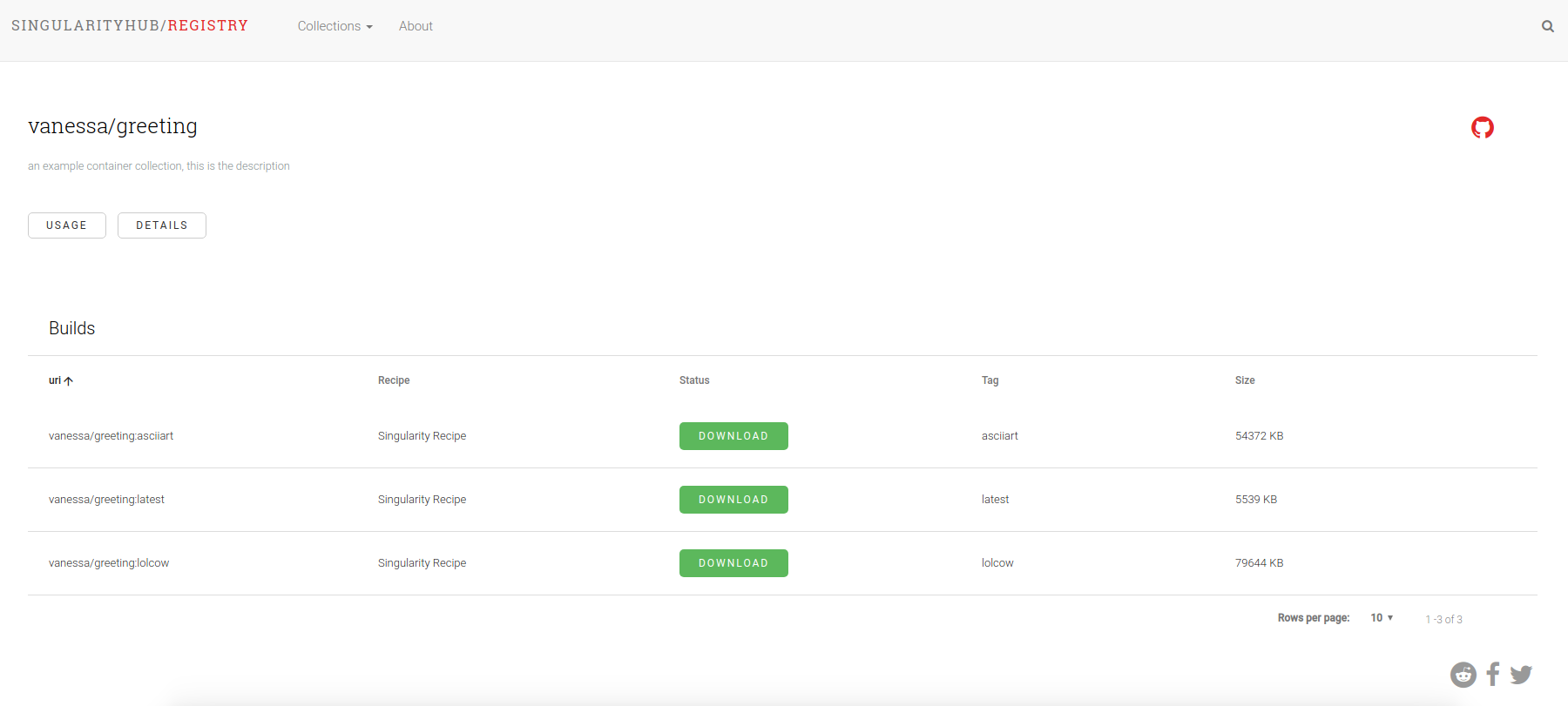
I won’t go into into details for setting it up, but here they are if you are interested. It comes down to forking (or downloading) the repository, and connecting it to GitHub Pages via a machine user.
How does it work?
This first example is a bit skeethy because I’m using artifact storage (free!) for my container storage :) But the general workflow is pretty simple:
- The user adds a Singularity (build definition file) under some folder (the namespace) and opens a pull request
- continuous integration builds the container, saves as an artifact, and generates the manifest
- on approval of the hold the files are pushed back to GitHub pages, updated the UI, API, and closing the pull request.
For the user interface, it’s all done via tricks with GitHub pages and Jekyll. For example, here we can grab a tags endpoint
$ curl https://singularityhub.github.io/registry/vanessa/fortune/tags/
{
"name": "vanessa/fortune",
"tags": [
"latest"
]
}
or a manifest!
$ curl https://singularityhub.github.io/registry/vanessa/fortune/manifests/latest/
{
"schemaVersion": 2,
"mediaType": "application/vnd.singularity.distribution.manifest.v2+json",
"config": {
"mediaType": "application/vnd.singularity.container.image.v1+json",
"size": 55056,
"digest": "sha256:bffb06f1d12ed52d62d51c60c46d1bfeba4530eb0ee563e2d3734e7a954537ce"
},
"layers": [
{
"mediaType": "application/vnd.singularity.image.squashfs",
"size": 55056,
"digest": "sha256:bffb06f1d12ed52d62d51c60c46d1bfeba4530eb0ee563e2d3734e7a954537ce",
"urls": ["https://57-167740989-gh.circle-artifacts.com/0/..."]
}
]
}
(I truncated the url so it wasn’t so ugly). That’s all generated for you when the pull request is merged. Seriously, you don’t need to think about it. I don’t know what a correct mediaType would be for a Singularity binary, so I made one up (hey Sylabs, do you guys have this figured out yet?)
What about the details and description for the collection?
The details and description are parsed directly from the README.md in the collection folder.
Why is it intuitive?
It’s easy to use because creating a new container build just coincides with adding a recipe (Singularity file) in a folder namespace. For example, if I want to add a container named “vanessa/avocado” I would create a folder “vanessa/avocado” in the root of the repository, and add a Singularity recipe in a manifests subfolder:
└── vanessa
└── avocado
└── manifests
└── latest
└── Singularity
After the pull request, the continuous integration would build my container, and generate these files for me:
└── vanessa
└── avocado
├── manifests
│ └── latest
│ ├── README.md
│ └── Singularity
├── README.md
└── tags
└── README.md
The sheer presence of the README.md files is the magic that generates the collection page, the tags endpoint, and the manifests. If I wanted to re-build a container? I could just delete the README.md for it.
$ rm vanessa/avocado/manifests/latest/README.md
The absence of the README.md file alongside the recipe is a flag to rebuild, and even when we delete, a record of all of our changes is maintained in the git history (thank you version control!) If I want to edit the description for the collection, or write lots of documentation for it, I could just edit the main collection README.md file (not the one you would delete with some frequency!).
What about other builders and storage?
If you are clever you’ll see that you can substitute any (remote) build and/or storage strategy with the artifact, and this would be a better design to not burden the CI with building / storing all the containers. This particular use case is an example (or maybe for the user that just has a small collection of containers to share). You can then just do some command line magic to get the container itself:
c=$(curl https://singularityhub.github.io/registry/vanessa/greeting/manifests/asciiart/ | jq --raw-output '.layers [] .urls [0]')
wget -O mrcontainer.sif $c
How does it scale?
The way this can scale is if the registry is relinquished of responsibility to build, and just receives pull requests to add metadata that has been built elsewhere (and perhaps checks that the metadata is valid). It will also be much faster building with an already built Docker base for Singularity (instead of a native install). I started with this simpler case because it’s much more challenging to keep separate GitHub repos in sync. Next I want to do an example with an external (Google Cloud) builder, and using GitHub actions so we don’t need to additional GitHub machine user. I just need to get some credits for testing this out. :)
TLDR
In summary, after set up and connection with CircleCI, it’s a very nice and easy workflow to change files, and open pull requests as the typical GitHub user normally would.
Why am I excited about this?
I’m really excited about the static registry because it empowers the user to “choose their own adventure” when it comes to assembling your build service, storage, and even the template for how your registry looks! Yes, you can make your registry blue, green, and customize the interface however your please. It’s your registry, and it’s version controlled and open source.
What comes next?
I’ll be working on other examples that use various builds and storage, and in the meantime, if anyone has a particular storage / builder setup they would like to test out (and have an example repo for) tell me and we can work on it together.
Suggested Citation:
Sochat, Vanessa. "Proof of Concept: The Static Registry." @vsoch (blog), 30 Jan 2019, https://vsoch.github.io/2019/static-registry/ (accessed 14 Jul 26).