Where do machine learning projects and web interfaces collide? If you are like me, you are used to a traditional “batch” style of machine learning - we start with big matrices of data (with some logical way to split into test and training data) and then we go through batch training and get some metric of accuracy using our test set. This works fairly well for most applications like static notebooks, research scenarios where you have access to a big filesystem or amounts of memory, or just on your local laptop using tensorflow, scikit-learn, or another standard ML library we’ve all come to love (or hate, depending on your view of the whole thing!) So what happens when you hit one of these issues?
- I have streaming data
- I need to deploy a web app and there isn't enough memory or storage for something
- I need my model to easily update over time
Oh no… too much data/memory chonk! What can we do?
A Story of Too Much
I was recently in this scenario. I was working on a fun personal projet, and had trained a pretty cool model to derive a clustering from software error messages, and was using Doc2Vec from Gensim. This meant I was:
- Generating a vector (embedding) for each error messages.
- Adding that to a massive data frame.
- Using dimensionality reduction (TSNE or umap) to view it
Everything was lovely and dandy until I got more data. I don’t think it was that much when we are talking about machine learning problems (N=260K), but it was enough that the last step was killed on my local machine. I then took it to our supercomputer, and after waiting forever and a half for a node, it still was killed. Now I could have sought out a bigger node (MOOOOOOAR POWER!) or optimized my computing strategy, but I stepped back for a second. You see, I wanted this model to be part of spack monitor, which meant that I would need to derive the visualization on a dinky web server. I’d also need to do the initial model building and update on the server. The solution I was developing wasn’t good enough. I would need to have some complicated setup to run nightly batch jobs to generate new embeddings and update the model, and then another (once daily perhaps) updated view of the embeddings. And I couldn’t just use a standard cloud server, I’d need something big. I knew it wouldn’t work.
Online Machine Learning
This led to a search for “streaming” and “machine learning” and I stumbled on the concept of online machine learning (online ML):
In computer science, online machine learning is a method of machine learning in which data becomes available in a sequential order and is used to update the best predictor for future data at each step, as opposed to batch learning techniques which generate the best predictor by learning on the entire training data set at once. Online learning is a common technique used in areas of machine learning where it is computationally infeasible to train over the entire dataset, requiring the need of out-of-core algorithms. It is also used in situations where it is necessary for the algorithm to dynamically adapt to new patterns in the data, or when the data itself is generated as a function of time, e.g., stock price prediction. Online learning algorithms may be prone to catastrophic interference, a problem that can be addressed by incremental learning approaches. - Wikipedia Authors
As you can see, this doesn’t just mean putting machine learning models online. It’s an entirely different way of thinking about ML, where instead of doing things in batches with big matrices, we instead learn one data point at a time, and can also make one prediction at a time. We might even add a data point for our model to learn, save an identifier for that addition, and provide a label for it later. A lot of these streaming methods are also neat because they have a temporal aspect, meaning that older samples are discarded as you move through time and have newer data. You can imagine this would work very well for models that are temporally changing. Also note that there are online machine learning techniques for both supervised and unsupervised methods.
River
Very quickly I stumbled on a library called river (and on GitHub) along with a Flask server component called chantilly, both the work of @MaxHalford, a data scientist at carbonfact that (like many a passionate developer) is working on online ML on the side. I recommend that you check out his blog and this post and this post in particular that I found really helpful for originally learning about online ML. If you’ve gone through an entire PhD and have never heard of it, it’s a hugely refreshing and awesome idea! I am not a machine learning specialist, however Max is, and he describes the design and ideas beautifully. I attended a talk by Max and I’ll also direct you to his set of slide and talks for your browsing!
Django River ML
Alrighty so back to dinosaur land. I was really excited about river. It’s set up to be “the next scikit-learn (or similar) but for online machine learning! Since spack monitor is a Django application, my first thought was to add river to it. But I decided I could do a lot more for the open source and ML communities if I could instead make a Django plugin, or “reusable app” that others could plug into their server! So long story short, that’s what I did. If you are a Django developer and want to easily use river, here are resources for you!
- Django River ML: the app that you can add to your server.
- riverapi: A Python module so you can easily interact with your server.
- the API specification: that defines server endpoints, in case you want to create a new tool.
How does it work?
Installation
If you are familiar with Django, this will make sense. If not, this section is basically adding
django-river-ml to a Django server. You will basically pip install it, and then add this to the Django settings.py file:
INSTALLED_APPS = (
...
'django_river_ml',
'rest_framework',
...
)
And also to expose URLs:
# Add django-river-ml’s URL patterns:
from django_river_ml import urls as django_river_urls
urlpatterns = [
...
url(r'^', include(django_river_urls)),
...
]
And of course all this is customizable - everything from the url prefix used to the URL exposed or to add authentication or not! Check out the settings to learn more.
Client Interaction
Okay great! You add these endpoints, which are basically going to allow you to:
- Upload a model you generate locally
- Learn from a trained model
- Get a prediction for a new piece of data
- Apply a label
- Get metrics, stats, or monitor server events.
For each of these “external” functions, the same can be accomplished from within the server. E.g., I could turn off all the externally exposed endpoints, and just use my own endpoints to parse and then present data to my river model. It’s very flexible for your use case! So now let’s take a look at what these interactions might look like.
Authentication
First, if your server requires authentication (e.g., you’ve generated a Django Restful token) you can basically just export the username and token to the environment for the client to find:
export RIVER_ML_USER=dinosaur
export RIVER_ML_TOKEN=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Authentication can be disabled, and actually this is the default to support the most common use case of you trying it out on your local machine. Of course for a production server you should be cautious about making this decision!
External Client
Next let’s instantiate a client:
from riverapi.main import Client
# This is the default, just to show how to customize
cli = Client("http://localhost:8000")
You might first check out information about the server:
# Basic server info (usually no auth required)
cli.info()
{'baseurl': 'https://prod-server',
'id': 'django_river_ml',
'status': 'running',
'name': 'Django River ML Endpoint',
'description': 'This service provides an api for models',
'documentationUrl': 'https://vsoch.github.io/django-river-ml',
'prefix': 'ml',
'storage': 'shelve',
'river_version': '0.9.0',
'version': '0.0.18'}
And then make and upload a model with river:
from river import linear_model, preprocessing
from river import preprocessing
# Upload a model
model = preprocessing.StandardScaler() | linear_model.LinearRegression()
# Save the model name for other endpoint interaction
model_name = cli.upload_model(model, "regression")
print("Created model %s" % model_name)
# Created model fugly-mango
And then learn or predict! River provides a bunch of datasets you can play with, and there is support to load them from sklearn. Here is learning:
from river import datasets
# Learn from some data
for x, y in datasets.TrumpApproval().take(100):
cli.learn(model_name, x=x, y=y)
And predicting:
# Make predictions
for x, y in datasets.TrumpApproval().take(10):
print(cli.predict(model_name, x=x))
And note how I’m not calling the first “training.” I don’t know if this is correct, but training makes me think of the batch approach. A streaming, incremental approach is more learning (over time). And then you might look at stats or metrics, or just monitor events!
cli.metrics(model_name)
{'MAE': 7.640048891289847,
'RMSE': 12.073092099314318,
'SMAPE': 23.47518046795208}
cli.stats(model_name)
{'predict': {'n_calls': 10,
'mean_duration': 2626521,
'mean_duration_human': '2ms626μs521ns',
'ewm_duration': 2362354,
'ewm_duration_human': '2ms362μs354ns'},
'learn': {'n_calls': 100,
'mean_duration': 2684414,
'mean_duration_human': '2ms684μs414ns',
'ewm_duration': 2653290,
'ewm_duration_human': '2ms653μs290ns'}}
# Stream events
for event in cli.stream_events():
print(event)
# Stream metrics
for event in cli.stream_metrics():
print(event)
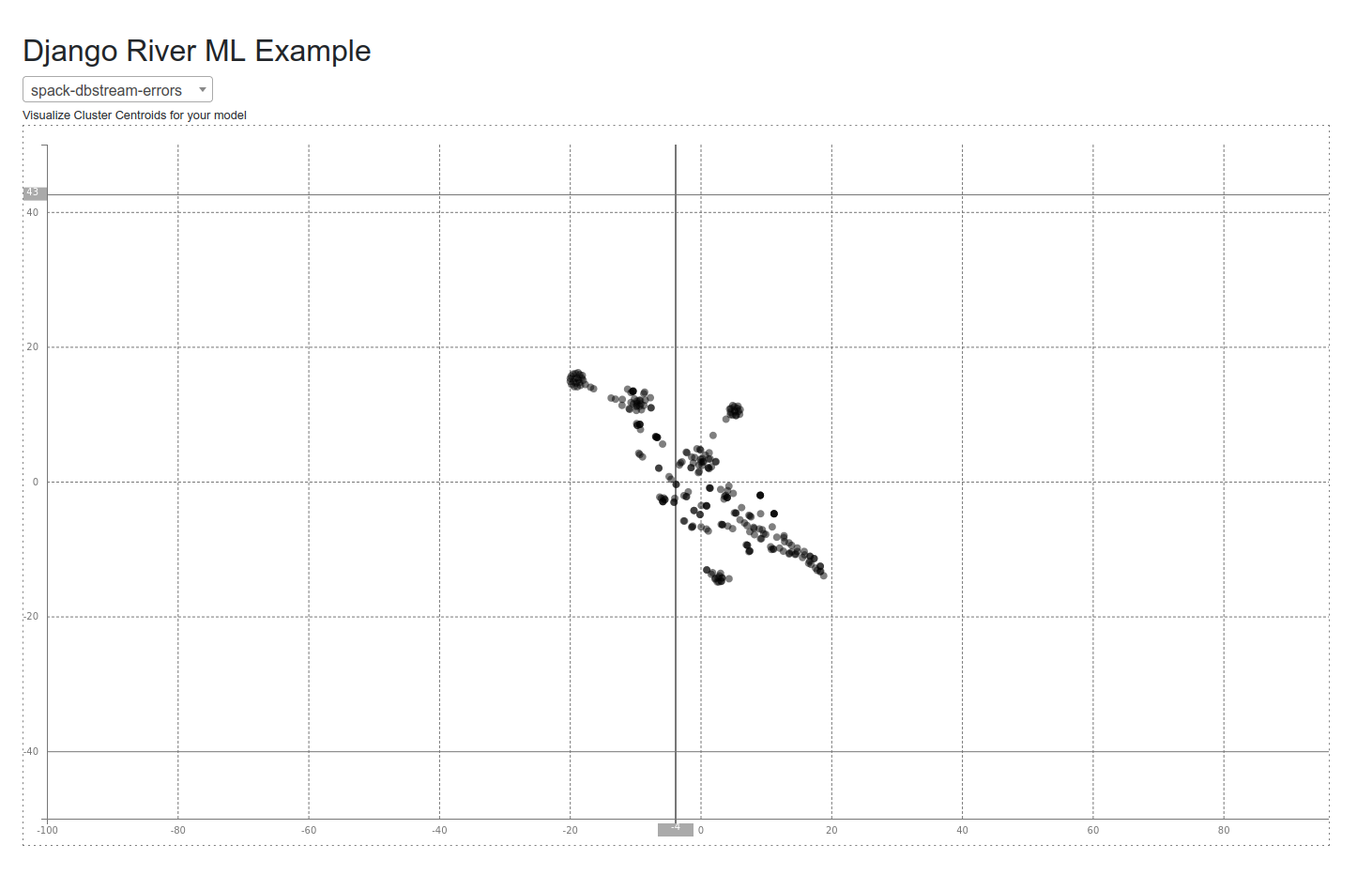
The examples above are for a server running on localhost (how I’ve been using it) but of course this could be a fully ceritified url. I think (for the time being) my favorite model is DBSTREAM because it’s a clustering that doesn’t require me to define a number of clusters ahead of time, and it’s been working quite well on some of my datasets.
And just for a quick glimpse, here is a visual of the cluster centroids for a subset of data that I’ve been testing with (after dimensionality reduction using TNSE). Indeed we see some structure!
Internal Client
If you want to interact with django-river-ml internally, we have a client for that! You’d import this directly from the module:
from django_river_ml.client import DjangoClient
client = DjangoClient()
That client is going to support the same kinds of functions that you might hit with an API call.
client.models()
['milky-despacito', 'tart-bicycle']
# A learning example
client.learn(
model_name,
ground_truth=ground_truth,
prediction=prediction,
features=features,
identifier=identifier,
)
See these pages for more examples.
Why should I care?
Okay, here is the most important part of the post. Online machine learning is a different (and newer) paradigm for machine learning, and if we can further develop the space we are going to be able to build a lot of cool applications using the tools! As someone who is strongly software engineer and likes to build things, this is a future I want to see. So if you have a problem that would be well supported by this paradigm, give it a shot! And please contribute to both river and django-river-ml - I can tell you from first-hand experience from a handful of issues and pull requests that the river community is welcoming, kind, and they have plans for making the library as awesome as it can be! Here is their contribution section. And if you are a Django person and want to contribute (or discuss features or changes for Django River ML), I’d love to have you!.
Suggested Citation:
Sochat, Vanessa. "Online Machine Learning." @vsoch (blog), 21 Mar 2022, https://vsoch.github.io/2022/online-machine-learning/ (accessed 14 Jul 26).