I’ve been working on an idea recently that I’m very excited about, and want to pause to share. In this post I’ll summarize the problem, a potential design, and then a simple example that demonstrates the proposed solution.
The Problem
As we’ve been doing more work, either running experiments or workflows, we consistently run into this problem.
My experiment/workflow generates file assets that I need to keep (for inspection later / for a next step)
For the most part, you can throw in a persistent volume, or even a host volume to share files between containers in pods, but to be frank, I find this really arduous. It’s usually the case that storage options take considerable setup (either with secrets or multiple helm configurations and very likely different strategies between clouds). And then when you work on the thing locally, you can’t use that same setup. I think I could justify a complex setup for a large (one time) experiment, but doing this many times over? It’s just a lot. The TLDR is that storage in Kubernetes is really hard, and it’s easier to (for the most part) avoid it. For this reason, much of our early work has run experiments that generate output to the console, and then we can use Kubernetes APIs to get the pod logs. But what did I really want? I wanted an ability to easily cache artifacts between steps, and not have to think too much about setting up volumes or storage. This is where the need for an artifact cache comes into the picture!
A Need for an Artifact Cache
My mind has been ruminating about this for a while. Earlier in the year (April 2023) we put together the OCI Registry as Storage (ORAS) CSI or ORAS Container Storage Interface. From the documentation:
The Container Storage Interface (CSI) is a standard for exposing arbitrary block and file storage systems to containerized workloads on Container Orchestration Systems (COs) like Kubernetes. Using CSI third-party storage providers can write and deploy plugins exposing new storage systems in Kubernetes without ever having to touch the core Kubernetes code.
In the context of ORAS, you could add ORAS artifacts on the fly to a pod, such as a binary or a configuration file. On a high level, it was an easy way to patch a container, but in that we are pulling the artifacts to a location on the node, it was a huge no-no to try to persist anything. But I kind of wished I could? 🤔️ This idea stayed in the back of my mind, because when we decided to refactor Snakemake to use modules and I started the snakemake-executor-kueue I again was faced with this problem, but on a larger scale, because I had steps in a workflow. My first effort over a few days in July (of this year, 2023) I tried out a simple idea in a very hard-coded sort of way. If you look at that specific commit, the example shows manually deploying an ORAS registry, and then each step of the workflow is explicitly pulling and pushing artifacts that are namespaced for the logic of the DAG. This allowed Snakemake to discover the files it needed at each step, and not poop out on me with all kinds of “missing output exception” 💩️! I had another use case bubbling up that would make me ruminate on the idea as something more solid, and this was more recent (October). I was starting to run experiments with the Metrics Operator that were more substantial than piping output to the terminal. They were generating xml files and png images of cool system diagrams (hwloc)! Seriously, let’s pause for a second and look at what hwloc can do!

That’s an “inf2.8xlarge” instance type from AWS, which is just one of the instance types I happened to get for a “can I get different spot instances and run LAMMPS” experiment I was prototyping. And here is the associated XML. Gosh, I love computers 🥰️. Anyway I digress! Given that we want to generate many output files, and often more than one file per experiment iteration, I knew that the previous way we had done things (LAMMPS output to the pod log, away!) wasn’t going to work. We needed an easy way to store artifacts (files or directories) on the fly, whether that be a step in a workflow (that needs to be retrieved again) or an experiment result (that just needs to be pulled at the end). This is where a lightbulb went off…
💡️ Could I create an operator that would provide an artifact cache for a namespace?
Or in simpler terms:
🤓️ A Kubernetes registry service for caching workflow or experiment artifacts.
It felt like a fairly simple idea. I would take the “hard coded” variant I imagined for the Snakemake Kueue operator and make it really easy to use. I was delayed on this quite a bit because of two talks, but was really eager to work on it. I first spec’d out a design in a document “projects for next year” (ha, as if I could really actually wait that long…) and quickly realized that the main features that I would need are an ability to label or annotate a pod with a signal that says “I want to save or retrieve an artifact” and then some ability to inject a sidecar container that would (somehow) perform those steps.
ORAS, OCI Registry As Storage
Before we jump into this design idea in more detail, let me convince you further that a registry is a good idea for workflows or experiment artifacts, period. If you aren’t familiar with ORAS, here is why I think it will work very well for this use case. The benefits of ORAS are that it is:
- An effective / efficient protocol for pushing/pulling artifacts from a namespaced registry
- Support for authentication / permissions (if needed, can be scoped to a namespace)
- Expecting artifacts that range from small to large
- Whatever content types we need, as long as it's a blob it will work
- Namespacing based on a workflow, experiment, or whatever you decide!
- With recent libraries, an ability to live patch an artifact (without retrieving the entire thing)
Registries historically were intended for container images, meaning that the layers (blobs or artifacts) were fairly large .tar.gz files, and on pull and run they would be assembled on the fly into a Docker image (or similar) via a manifest. I do recognize that for very big workflow artifacts, we might need to add (again, those cloud volumes that are hard to setup) to the registry itself. But (I think) the good news is that this can be done once for a workflow or experiment setup. Likely I can also abstract away some of the complexity given an operator. I’ll work on this more when the need arises, because now the registry works well for tiny artifacts that I’m using to test, or for the experiments we are running that primarily generate logs and images. I suspect for many (most?) use cases, the artifacts to save just aren’t that big, but that will wait to be seen.
On a high level, what ORAS has done (that to this day I still think is pure 🤌️) is instead of using the registry just for one layer type (e.g., .tar.gz), allowing any type of blob (the artifact) and customization of the manifest (that designates metadata and content types for the blobs). In simple terms, with an OCI registry (and ORAS as the client to handle interaction with it) running alongside a workflow or set of experiments, we can easily use it to cache whatever artifacts we need cached!
The Design
Now that we understand the problem let’s talk about my early thinking for a solution. The design was going to work as follows. Note that this is a derivative of what I wrote up before I had implemented anything.
- Create an operator that creates the ORAS registry to exist in a namespace and be provided via a service.
- Watch for annotations (coming from any Kubernetes workload abstraction that uses pods to run applications)
- The annotations provide metadata about storage paths and needs.
- The controller injects a sidecar to marked pods using a mutating admission webhook to manage registry interaction.
- The workflow would then proceed to run as expected, but with access to the needed assets from previous step(s)
- When the main application is done, the sidecar can (optionally) upload the result to an artifact for the next step.
- If desired, the user (at the end) can pull any artifacts that are needed to persist or save, and then cleanup.
For step 2, I chose annotations over labels because annotations allow for namespacing to the operator and special characters like file paths, while labels do not. For step 4, I didn’t think beyond the basic “make it work” of having the sidecar. I suspected that the sidecar would need the ORAS client installed, optional credentials (although I haven’t added support for that yet) and would need to handle pulling and pushing. I also knew that I’d need some logic to ensure that the main container entrypoint waits for that setup, and the ORAS sidecar consequently waits for the application to finish before saving any artifacts. After the design above, I decided to start with a very simple case of creating a pod that would write a file, and then saving it to an artifact in the registry, and pulling it finally to my local machine. That would be an appropriate “hello world” example I think. 👋️
Implementation
Now we can move from “idea to a design” to how I like to work on the details for a design, which means the actual (in this case, first) implementation. Here is diagram that shows how most of it works, and I will go through the steps in detail (now that I know it)!
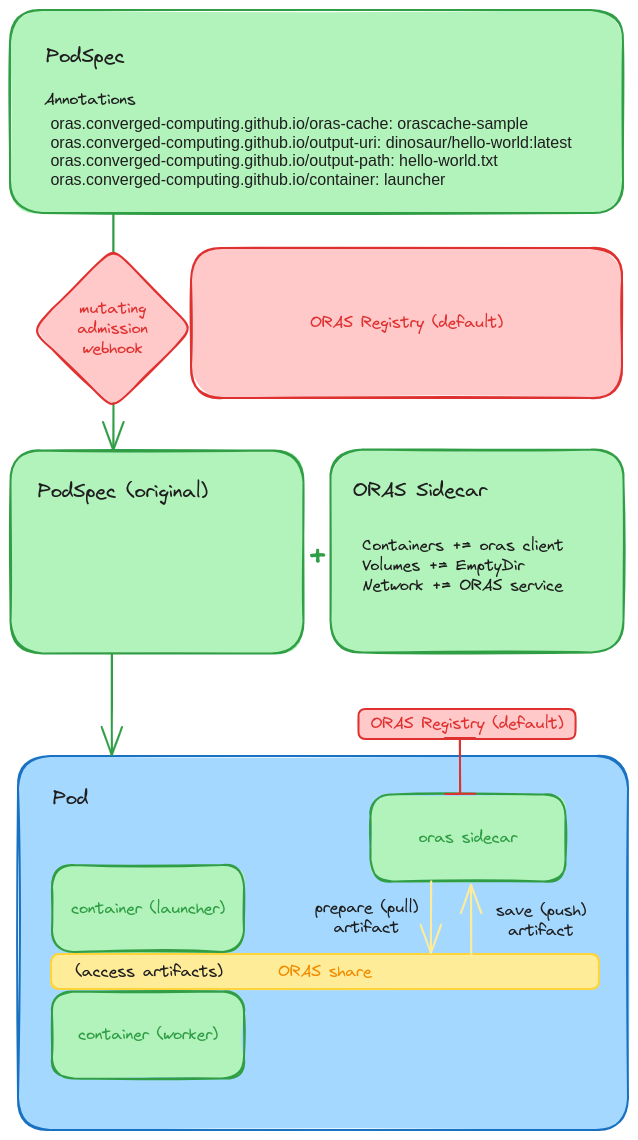
1. Registry
We deploy the ORAS Operator as a custom resource definition, meaning we deploy a registry service to a namespace, and it will be interacted with via a mutating admission webhook. The registry will be accessible via a headless service in that namespace. This is the second block of red in the picture above, and the actual custom resource definition for this is fairly simple:
apiVersion: cache.converged-computing.github.io/v1alpha1
kind: OrasCache
metadata:
name: orascache-sample
spec:
image: ghcr.io/oras-project/registry:latest
There isn’t much to customize, unless you want a specific version (container) for the ORAS client. The above is the default, so I could have left that out, but then it would have felt so empty! 😆️ We will add more to this as it is needed.
2. PodSpec
In the very top (green) panel, we see a PodSpec (for some application) that has annotations for the ORAS Operator, or more specifically, the registry running in the same namespace. Any pod that is admitted into Kubernetes (and note that this can be a pod that is generated from a Job, JobSet, or Deployment, another operator, or really any means) is going to be inspected for these annotations. In the picture below, we have the following annotations under the “oras.converged-computing.github.io” namespace:
- oras-cache: is the name of the cache we are targeting (e.g., the name from the OrasCache spec created
- output-uri: is the unique resource identifier to save our artifact to
- output-path: is the path in the application container where the artifact is expected (a single file or directory)
- container: the container to target that will generate the artifact file.
For the above, the output-uri would typically be managed by a workflow tool. If you are running iterations of an experiment, you might just vary the tag to correspond to the iteration (e.g., “metrics/lammps:iter-0” through “metrics/lammps:iter-N”. Note that we don’t specify an “input-uri” because we don’t need to retrieve an artifact in advance, but if we did, we’d need an “input-path” too if we wanted to change it from the working directory. Finally, note that although the “launcher” container is expected to have the artifact (meaning it will have an ORAS sidecar added to handle the moving of assets) the other containers in the pods will also have access to the same empty volume and headless service. This is done assuming I don’t know what you want to do (and not providing consistency here could lead to trouble).
Finally, I am not convinced that the mutating admission webhook watching the Pod is the right level of abstraction. Given the use cases that I have, I think a Job (that has a PodSpec Template to create one or more pods) would be a better choice. I haven’t changed it yet, pending further feedback and testing. It could be that we just allow the user deploying the operator to decide on the object to mutate (this is an approach I’d like). If you have thoughts, please comment on this issue. You can see a full table of annotations here.
3. Mutating Admission Webhook
The magic happens with the mutating admission webhook (red diamond), which detects the pod creation, finds the annotations, and knows that the pod is targeted for mutation! In this case (third row, green panels) we see that the mutation means adding an ORAS sidecar. This include a sidecar container with an ORAS client ready to Go (no pun intended), a Volume with an empty directory, and the selector for the oras headless service. Also note that (not shown in this diagram) we modify the entrypoint. Specifically, logic is added to the start of the application pod to wait for ORAS to retrieve artifacts (if needed) and put them in place. The original entrypoint is then run, and logic is added to indicate that the application is done. Both of these use simple file indicators.
4. Pod Logic
Now we can go into the logic of the different containers in the pod. How do artifacts get pulled and moved where they need to be, and then further saved? Let’s walk through an example, illustrated by the last row (blue Pod). When the containers first come up (note we have a launcher, a worker, and an oras sidecar), the application container “launcher” is waiting to see a file indicator that ORAS (oras sidecar) is done. Equivalently, When the “launcher” is running, the ORAS sidecar is waiting to see an indicator that the application is done. More specifically this means that:
- An ORAS input artifact (if defined) is pulled and moved into the ORAS share.
- The file indicator is written so the application container can go.
- It optionally moves the artifact from ORAS share to some other path (specified in the annotation metadata)
- The application (original entrypoint) is run
- The application finishes, and the specified output is moved back to the ORAS share
- The file indicator is written by the application container
- The ORAS sidecar sees the application is done, and pushes the artifact.
In the picture above, you can see the ORAS sidecar doing push and pull operations on behalf of the pods, and interacting with the registry service (that is shared by the namespace). The application containers get access to the artifacts via the ORAS share, and extra logic is added to the entrypoints to ensure that files or directories are moved to where they need to be.
And that’s it! Since both containers need to cleanup for something like a Job to finish, in practice when the application finishes and ORAS pushes, in the case of a Job (that has a Completed state) it will complete and go away. But you can rest assured your experiment result or workflow step has been pushed to the ORAS Registry cache, and is ready to be used for a next step (or just retrieved by you). Hooray! 🎉️ A very simple example of this can be found here to run and save metric experiment assets (xml, png, and log files). I was really happy when this ran the first time, and excited to extend it to more complex things (workflows).
5. Workflow
Here is a higher level picture of what this might look like for a workflow:
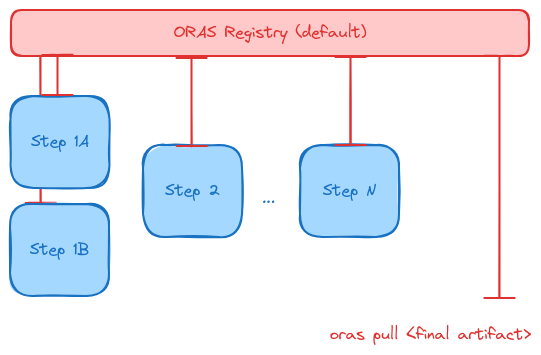
In the above, a workflow tool is adding annotations to pod (or Job -> PodSpec Templates) programmatically, and the inputs/outputs are retrieved for each step, ensuring that the needed artifacts are retrieved and saved for each step. After the last step, the workflow runner can create a simple port forward to pull some final artifact or result to the local machine. Likely the intermediate artifacts could also be of interest, but it’s not entirely necessary.
A Simple Example
Let’s walk through a simple example. For the hello world example, see here. I want to demonstrate something slightly cooler, running metrics that generate output. Without the ORAS operator I’d need a host volume for local development, and either to “kubectl cp” to get the final files, or an actual storage setup. We will assume creating the oras registry (yaml already shown above) is done. Here is an example YAML that will run LAMMPS using the Metrics Operator, but instead of just writing output to the terminal, we also save to lammps.out in the present working directory:
apiVersion: flux-framework.org/v1alpha2
kind: MetricSet
metadata:
labels:
app.kubernetes.io/name: metricset
app.kubernetes.io/instance: metricset-sample
name: lammps-0
spec:
pods: 2
# This puts the job on the oras registry network
# We do this since it's only possible to add one headless service (at least it seems)
serviceName: oras
pod:
annotations:
# the name of the cache for the workflow, the name from oras.yaml
oras.converged-computing.github.io/oras-cache: oras
oras.converged-computing.github.io/container: launcher
oras.converged-computing.github.io/output-uri: metric/lammps:iter-0
oras.converged-computing.github.io/output-path: /opt/lammps/examples/reaxff/HNS/lammps.out
oras.converged-computing.github.io/debug: "true"
metrics:
- name: app-lammps
options:
command: mpirun --hostfile ./hostlist.txt -np 4 -ppn 2 lmp ... 2>&1 | tee -a lammps.out
Note that when I was developing this example I ran into a few interesting problems, namely this one and this one. Thanks to Kevin Hannon (now at RedHat) for the tips. My fix was to change the mutating webhook to only be on CREATE but it looks like I could have also updated Kubernetes. Then they terminated! Cue terminator voice… 🤖️
So for a high level, we basically are running the Metrics Operator with LAMMPS (and it creates JobSet that have pods underneath it all) that are being given annotations that say “please save your metrics experimental results to our registry!” I could create the experiments, actually for each of LAMMPS and for running HWLOC:
$ kubectl apply -f data/
metricset.flux-framework.org/hwloc-0 created
metricset.flux-framework.org/lammps-0 created
One bug(?) I ran into (that I was not expecting) is not being able to add a single pod to two headless services. The reason is because ORAS has one, and the Metrics Operator has a second (to run LAMMPS). However, despite both services being created and the selector labels being added to the pods, only one showed up. As a workaround I had to use the ORAS space, which (unfortunately) meant I could only run one LAMMPS experiment at once, as running more than one (in the same namespace) would mean they would ALL be on the same network (in terms of DNS). Maybe that doesn’t matter? But it made me uneasy enough to not do it. Sometimes when I don’t understand something I take a more conservative approach until I talk to someone about it. Then we could look at the pods, and see two containers for each of the targeted LAMMPS or HWLOC pods. This was the “container” annotation, and ensured that we didn’t add a sidecar to a container that didn’t need one.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hwloc-0-m-0-0-zlf9d 2/2 Running 0 6s
lammps-0-l-0-0-k9ztb 2/2 Running 0 6s
lammps-0-w-0-0-hg49p 1/1 Running 0 6s
oras-0 1/1 Running 0 83s
The others (e.g., the LAMMPS workers) have the network and other pod customization, but will not have the sidecar added. You can now wait until they are finished:
kubectl get pods
NAME READY STATUS RESTARTS AGE
hwloc-0-m-0-0-528kq 0/2 Completed 0 109s
lammps-0-l-0-0-fdckq 0/2 Completed 0 109s
oras-0 1/1 Running 0 16m
And just to be clear - “finished” means that the sidecar container with ORAS was setup, the applications ran (LAMMPS or HWLOC) and then their artifacts were moved and pushed to the registry. The containers then both exit, allowing the Job to complete. Nice! Now let’s inspect some logs to see what the output looks like, starting with LAMMPS.
LAMMPS
When LAMMPS is done running you can look at the logs. Here is the application “launcher” container. Note that the little bit at the top is the piece that is injected by our operator.
$ kubectl logs lammps-0-l-0-0-7ppcg
...
Expecting: <artifact-input> <artifact-output> <command>...
Full provided set of arguments are NA /opt/lammps/examples/reaxff/HNS/lammps.out /bin/bash /metrics_operator...
Command is /bin/bash /metrics_operator/launcher.sh
Artifact input is NA
Artifact output is /opt/lammps/examples/reaxff/HNS/lammps.out
🟧️ wait-fs: 2023/11/04 16:42:55 wait-fs.go:40: /mnt/oras/oras-operator-init.txt
🟧️ wait-fs: 2023/11/04 16:42:55 wait-fs.go:49: Found existing path /mnt/oras/oras-operator-init.txt
METADATA START {"pods":2,"metricName":"app-lammps","metricDescription":"LAMMPS molecular dynamic simulation", ...}}
METADATA END
Sleeping for 10 seconds waiting for network...
METRICS OPERATOR COLLECTION START
METRICS OPERATOR TIMEPOINT
LAMMPS (29 Sep 2021 - Update 2)
OMP_NUM_THREADS environment is not set. Defaulting to 1 thread. (src/comm.cpp:98)
using 1 OpenMP thread(s) per MPI task
Reading data file ...
triclinic box = (0.0000000 0.0000000 0.0000000) to (22.326000 11.141200 13.778966) with tilt (0.0000000...
2 by 1 by 2 MPI processor grid
reading atoms ...
304 atoms
reading velocities ...
304 velocities
read_data CPU = 0.002 seconds
Replicating atoms ...
triclinic box = (0.0000000 0.0000000 0.0000000) to (44.652000 22.282400 27.557932) with tilt (0.0000000...
2 by 1 by 2 MPI processor grid
bounding box image = (0 -1 -1) to (0 1 1)
bounding box extra memory = 0.03 MB
average # of replicas added to proc = 5.00 out of 8 (62.50%)
2432 atoms
replicate CPU = 0.001 seconds
Neighbor list info ...
update every 20 steps, delay 0 steps, check no
max neighbors/atom: 2000, page size: 100000
master list distance cutoff = 11
ghost atom cutoff = 11
binsize = 5.5, bins = 10 5 6
2 neighbor lists, perpetual/occasional/extra = 2 0 0
(1) pair reax/c, perpetual
attributes: half, newton off, ghost
pair build: half/bin/newtoff/ghost
stencil: full/ghost/bin/3d
bin: standard
(2) fix qeq/reax, perpetual, copy from (1)
attributes: half, newton off, ghost
pair build: copy
stencil: none
bin: none
Setting up Verlet run ...
Unit style : real
Current step : 0
Time step : 0.1
Per MPI rank memory allocation (min/avg/max) = 103.8 | 103.8 | 103.8 Mbytes
Step Temp PotEng Press E_vdwl E_could Volume
0 300 -113.27833 437.52118 -111.57687 -1.7014647 27418.867
10 299.38517 -113.27631 1439.2449 -111.57492 -1.7013814 27418.867
20 300.27106 -113.27884 3764.3565 -111.57762 -1.7012246 27418.867
30 302.21063 -113.28428 7007.709 -111.58335 -1.7009363 27418.867
40 303.52265 -113.28799 9844.8297 -111.58747 -1.7005186 27418.867
50 301.87059 -113.28324 9663.0567 -111.58318 -1.7000523 27418.867
60 296.67806 -113.26777 7273.8146 -111.56815 -1.6996137 27418.867
70 292.19998 -113.25435 5533.6324 -111.55514 -1.6992157 27418.867
80 293.58677 -113.25831 5993.3848 -111.55946 -1.6988534 27418.867
90 300.62636 -113.27925 7202.8542 -111.58069 -1.6985592 27418.867
100 305.38275 -113.29357 10085.75 -111.59518 -1.6983875 27418.867
Loop time of 12.5347 on 4 procs for 100 steps with 2432 atoms
Performance: 0.069 ns/day, 348.186 hours/ns, 7.978 timesteps/s
85.9% CPU use with 4 MPI tasks x 1 OpenMP threads
MPI task timing breakdown:
Section | min time | avg time | max time |%varavg| %total
---------------------------------------------------------------
Pair | 4.8613 | 6.4139 | 9.1093 | 64.6 | 51.17
Neigh | 0.13942 | 0.15179 | 0.18031 | 4.3 | 1.21
Comm | 0.60957 | 3.3044 | 4.8564 | 89.9 | 26.36
Output | 0.0017551 | 0.0018499 | 0.0019553 | 0.2 | 0.01
Modify | 2.6326 | 2.6617 | 2.6746 | 1.1 | 21.23
Other | | 0.001108 | | | 0.01
Nlocal: 608.000 ave 612 max 604 min
Histogram: 1 0 0 0 0 2 0 0 0 1
Nghost: 5737.25 ave 5744 max 5732 min
Histogram: 1 0 1 0 0 1 0 0 0 1
Neighs: 231539.0 ave 233090 max 229970 min
Histogram: 1 0 0 0 1 1 0 0 0 1
Total # of neighbors = 926155
Ave neighs/atom = 380.82031
Neighbor list builds = 5
Dangerous builds not checked
Total wall time: 0:00:12
METRICS OPERATOR COLLECTION END
And here is the ORAS sidecar that is waiting for the run to finish:
$ kubectl logs lammps-0-l-0-0-7ppcg -c oras
Expecting: <pull-from> <push-to>
Full provided set of arguments are NA oras-0.oras.default.svc.cluster.local:5000/metric/lammps:iter-0
Artifact URI to retrieve is: NA
Artifact URI to push to is: oras-0.oras.default.svc.cluster.local:5000/metric/lammps:iter-0
🟧️ wait-fs: 2023/11/04 16:42:50 wait-fs.go:40: /mnt/oras/oras-operator-done.txt
🟧️ wait-fs: 2023/11/04 16:42:50 wait-fs.go:53: Path /mnt/oras/oras-operator-done.txt does not exist yet, sleeping 5
🟧️ wait-fs: 2023/11/04 16:42:55 wait-fs.go:53: Path /mnt/oras/oras-operator-done.txt does not exist yet, sleeping 5
🟧️ wait-fs: 2023/11/04 16:43:00 wait-fs.go:53: Path /mnt/oras/oras-operator-done.txt does not exist yet, sleeping 5
🟧️ wait-fs: 2023/11/04 16:43:05 wait-fs.go:53: Path /mnt/oras/oras-operator-done.txt does not exist yet, sleeping 5
🟧️ wait-fs: 2023/11/04 16:43:10 wait-fs.go:53: Path /mnt/oras/oras-operator-done.txt does not exist yet, sleeping 5
🟧️ wait-fs: 2023/11/04 16:43:15 wait-fs.go:53: Path /mnt/oras/oras-operator-done.txt does not exist yet, sleeping 5
🟧️ wait-fs: 2023/11/04 16:43:20 wait-fs.go:49: Found existing path /mnt/oras/oras-operator-done.txt
Uploading fff26963dcb1 .
Uploaded fff26963dcb1 .
Pushed [registry] oras-0.oras.default.svc.cluster.local:5000/metric/lammps:iter-0
Digest: sha256:d01ff185fdc0974ac7ea974f0e5279ead62d270cfb38b57774ad33d9ea25ed33
Likely the time we wait to check could be a variable, as 5 seconds is fairly frequent. I can add this at some point when it is warranted.
HWLOC
The same can be seen for HWLOC. Here is the main log (that generates the architecture xml, etc).
$ kubectl logs hwloc-0-m-0-0-nh66b
Expecting: <artifact-input> <artifact-output> <command>...
Full provided set of arguments are NA /tmp/analysis /bin/bash /metrics_operator/entrypoint-0.sh
Command is /bin/bash /metrics_operator/entrypoint-0.sh
Artifact input is NA
Artifact output is /tmp/analysis
🟧️ wait-fs: 2023/11/04 17:37:28 wait-fs.go:40: /mnt/oras/oras-operator-init.txt
🟧️ wait-fs: 2023/11/04 17:37:28 wait-fs.go:49: Found existing path /mnt/oras/oras-operator-init.txt
METADATA START {"pods":1,"metricName":"sys-hwloc","metricDescription":"install hwloc for inspecting ..."]}}
METADATA END
METRICS OPERATOR COLLECTION START
mkdir -p /tmp/analysis
METRICS OPERATOR TIMEPOINT
lstopo /tmp/analysis/architecture.png
METRICS OPERATOR TIMEPOINT
hwloc-ls /tmp/analysis/machine.xml
METRICS OPERATOR TIMEPOINT
METRICS OPERATOR COLLECTION END
bin etc lib32 metrics_operator proc run tmp
boot home lib64 mnt product_name sbin usr
dev inputs libx32 opt product_uuid srv var
entrypoint.sh lib media oras-run-application.sh root sys
And here is the ORAS sidecar:
$ kubectl logs hwloc-0-m-0-0-nh66b -c oras
Expecting: <pull-from> <push-to>
Full provided set of arguments are NA oras-0.oras.default.svc.cluster.local:5000/metric/hwloc:iter-0
Artifact URI to retrieve is: NA
Artifact URI to push to is: oras-0.oras.default.svc.cluster.local:5000/metric/hwloc:iter-0
🟧️ wait-fs: 2023/11/04 17:37:22 wait-fs.go:40: /mnt/oras/oras-operator-done.txt
🟧️ wait-fs: 2023/11/04 17:37:22 wait-fs.go:53: Path /mnt/oras/oras-operator-done.txt does not exist yet, sleeping 5
🟧️ wait-fs: 2023/11/04 17:37:27 wait-fs.go:53: Path /mnt/oras/oras-operator-done.txt does not exist yet, sleeping 5
🟧️ wait-fs: 2023/11/04 17:37:32 wait-fs.go:49: Found existing path /mnt/oras/oras-operator-done.txt
Uploading 74bf636ebdde .
Uploaded 74bf636ebdde .
Pushed [registry] oras-0.oras.default.svc.cluster.local:5000/metric/hwloc:iter-0
Digest: sha256:5209373deb3ce18e01943cbee8eb0da2a9f4929e636c85f9e49e85074b441714
Again, we see in the second that the artifact path and unique resource identifier is known, the file indicator is detected, and it’s pushed to the registry. For those interested, that wait-fs tool is one that I developed for little operations like this, and it is called goshare. And of course at this point, you can cleanup your jobs. Your artifacts are stored with the registry. Let’s get em’!
Download
While they are better ways to do this, we can easily create a port forward to interact with the registry. In one terminal:
$ kubectl port-forward oras-0 5000:5000
Forwarding from 127.0.0.1:5000 -> 5000
Forwarding from [::1]:5000 -> 5000
Handling connection for 5000
Handling connection for 5000
Note that you will need ORAS Installed on your local machine.
$ oras repo ls localhost:5000/metric
hwloc
lammps
There they are! Now let’s try listing tags under each. For this simple experiment, we had the tag correspond to the iteration, and we only had one (index 0) for each. You can imagine running more complex setups than that.
$ oras repo tags localhost:5000/metric/lammps
iter-0
$ oras repo tags localhost:5000/metric/hwloc
iter-0
And now the moment of truth! let’s download the data. Note that if you are extracting multiple tags (with files of the same name) you likely want to do this programmatically and into organized directories. If you don’t use the Go-based oras client (which is good imho) you can use the Oras Python SDK instead (I maintain it). Let’s just dump these into a data directory:
cd data
oras pull localhost:5000/metric/lammps:iter-0 --insecure
oras pull localhost:5000/metric/hwloc:iter-0 --insecure
And there you have it! The single file for lammps (with output) and the “/tmp/analysis” directory with hwloc output (likely recommended approach to target a directory for >1 file)!
$ tree .
.
├── analysis
│ ├── architecture.png
│ └── machine.xml
├── hwloc-iter-0.yaml
├── lammps-iter-0.yaml
└── lammps.out
1 directory, 5 files
Next Steps
I am so excited about this I can’t tell you - take the above and apply it to a workflow? We can run workflows (with different steps) in Kubernetes without needing to mount some complex storage! This is what I will work on next. <3
More specifically, I am going to go back to the Snakemake executor Kueue plugin and try to update it to use this operator, bringing an actual DAG into the picture and thinking about automating the annotations for the inputs and outputs for Snakemake. This should be easier than I suspect because Snakemake typically operates at one root, and it will be really cool to just have the user deploy the registry and then have the executor plugin do all the work.
Stay tuned! 🎹️
Suggested Citation:
Sochat, Vanessa. "Kubernetes Artifact Cache." @vsoch (blog), 04 Nov 2023, https://vsoch.github.io/2023/oras-kubernetes-cache/ (accessed 14 Jul 26).