1. SLURM Job Manager, smanage
Slurm Manage, for submitting and reporting on job arrays run on slurm
Practices for Reproducible Research
This is a followup to our original post that described how to get access to a jupyter notebook on Sherlock with port forwarding! Today we will extend the example to a new set of sbatch scripts that will start up a jupyter notebook with tensorflow. Want a GPU? We can do that too. If you want to container-based verison of this tutorial (yes, you can deploy jupyter from a container too!) then see this post. Let’s get started!
Today we are going to do the following:
For more background, see the original post. For these instructions, you should be careful about opening and closing your terminal sessions. If you find a command hanging or failing, you might need to re-authenticate the session with your password, or you might be entering the wrong password.
First, clone the repository, and remember the location. You will generate a parameters flie
params.sh that you can go back to and use again.
git clone https://github.com/vsoch/forward
cd forward
As a reminder from the previous post, here are the files that we have to work with.
├── end.sh (-- end a session
├── resume.sh (-- resume a started session
├── sbatches (-- batch scripts you can run to forward a port to!
├── jupyter.sbatch
└── tensorboard.sbatch
├── setup.sh (-- run once to set up the tool
└── start.sh (-- how you start a connection
You will need to generate a file of parameters to source before using the tool. Importantly, if you want to use tensorflow with a gpu, you should select the partition to be “gpu” when it asks you.
$ bash setup.sh
Sherlock username > tacocat
Next, pick a port to use. If someone else is port forwarding using that
port already, this script will not work. If you pick a random number in the
range 49152-65335, you should be good.
Port to use > 56143
Next, pick the sherlock partition on which you will be running your
notebooks. If your PI has purchased dedicated hardware on sherlock, you can use
that partition. Otherwise, leave blank to use the default partition (normal).
Sherlock partition (default: normal) > gpu
Next, pick the path to the browser you wish to use. Will default to Safari.
Browser to use (default: /Applications/Safari.app/) > /usr/bin/firefox
Notice that I’ve changed the default browser (Safari on a Mac) to firefox on Ubuntu. Also note that I entered “gpu” for my partition. The resulting file is a simple text file:
$ cat params.sh
USERNAME="tacocat"
PORT="56143"
PARTITION="gpu"
BROWSER="/usr/bin/firefox"
MEM="20G"
TIME="8:00:00"
Follow the instructions here to set up your Sherlock credentials. You
can see what you have by looking at your ~/.ssh/config:
cat ~/.ssh/config
Don’t have the file? You can use a helper script in the repository to generate it. There is a helper script for Sherlock:
ls hosts/
sherlock_ssh.sh
and when you run it, the configuration is printed to the screen:
$ bash hosts/sherlock_ssh.sh
Sherlock username > tacocat
Host sherlock
User tacocat
Hostname sh-ln03.stanford.edu
GSSAPIDelegateCredentials yes
GSSAPIAuthentication yes
ControlMaster auto
ControlPersist yes
ControlPath ~/.ssh/%l%r@%h:%p
or just do the entire thing programatically:
bash hosts/sherlock_ssh.sh >> ~/.ssh/config
For local jupyter usage, set up your jupyter notebook password, for either version for Python 2 and/or 3. I wound up loading both modules and setting the same password, because I knew I’d forget.
$ module load py-jupyter/1.0.0_py36
# and do the same for py-jupyter/1.0.0_py27
$ which jupyter
/share/software/user/open/py-jupyter/1.0.0_py36/bin/jupyter
# Set the password
jupyter notebook password
Also make sure you have google and protobuf installed. The Python2 scripts loads protobuf as a module, but I did this anyway just in case.
$ pip install protobuf --user
$ pip3 install protobuf --user
$ pip install google --user
$ pip3 install google --user
Now we are back on our local machine. Here are the general commands to start and stop sessions. In the tutorial below, we will walk through using Jupyter notebook.
bash start.sh singularity-jupyte
We’ve already reviewed how to start a session in the previous post, now we will just go over how to start the tensorflow jupyter notebook, using the password from above. If you want more verbosity, see the previous post. The general command for start.sh looks like this:
bash start.sh <software> <path>
The above command will submit the job, forward the port, and show you the log that has your token password to enter into the url. The command to run jupyter notebook with tensorflow (using the modules provided on Sherlock) looks like this:
$ bash start.sh py2-tensorflow /path/to/dir
== Checking for previous notebook ==
No existing py2-tensorflow jobs found, continuing...
== Getting destination directory ==
== Uploading sbatch script ==
py2-tensorflow.sbatch 100% 169 0.2KB/s 00:00
== Requesting GPU ==
== Submitting sbatch ==
sherlock sbatch --job-name=py2-tensorflow --partition=gpu --gres gpu:1 --output=/home/users/vsochat/forward-util/py2-tensorflow.out --error=/home/users/vsochat/forward-util/py2-tensorflow.err --mem=20G --time=8:00:00 /home/users/vsochat/forward-util/py2-tensorflow.sbatch 56143 "/scratch/users/vsochat"
Submitted batch job 22351236
== Waiting for job to start, using exponential backoff ==
Attempt 0: not ready yet... retrying in 1..
Attempt 1: not ready yet... retrying in 2..
Attempt 2: not ready yet... retrying in 4..
Attempt 3: not ready yet... retrying in 8..
Attempt 4: not ready yet... retrying in 16..
Attempt 5: not ready yet... retrying in 32..
Attempt 6: resources allocated to sh-17-30!..
sh-17-30
notebook running on sh-17-30
== Setting up port forwarding ==
ssh -L 56143:localhost:56143 sherlock ssh -L 56143:localhost:56143 -N sh-17-30 &
== Connecting to notebook ==
Open your browser to http://localhost:56143
When you open your browser to the address, you will see a prompt for the password that you created previously. And when you are ready to be done, or you’ve left and want to come back later:
# Resume a session
bash resume.sh <name>
bash resume.sh py2-tensorflow`
# End a session
bash end.sh <name>
bash end.sh py2-tensorflow`
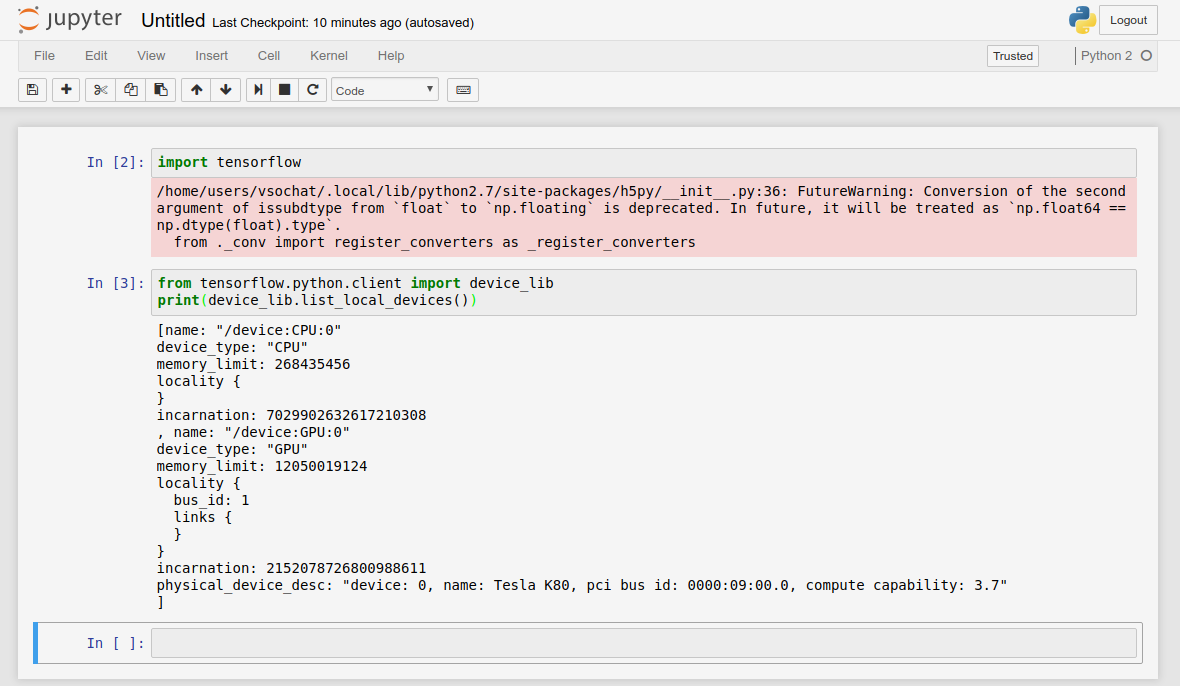
Once you have jupyter running, you want to make sure you select the python kernel corresponding to the one for your job! For our tutorial, we loaded python 2, so we would want to create a Python 2 notebook. Once in the notebook, here is a command that will let you check the devices available:
import tensorflow
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 7029902632617210308
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 12050019124
locality {
bus_id: 1
links {
}
}
incarnation: 2152078726800988611
physical_device_desc: "device: 0, name: Tesla K80, pci bus id: 0000:09:00.0, compute capability: 3.7"
]
Tensorflow is really buggy, and this solution is a bit hacky, but when you get it up and running, it really is a great workflow! That said, I want to help you to resolve issues that you might run into, so I’ve written up some common pitfalls that I hit during development. If you still need help, please reach out to our group!
There is a missing module!
This actually happened for me - I got an error message that there wasn’t a module called google protobuf. This is a bug with the installation of tensorflow on sherlock, because it should be loaded if it’s required. No fear! You can fix it yourself, and even from your terminal. First, do this:
import os
os.system("pip install --user protobuf")
And then restart the kernal from the interface to have changes take effect (you will get some glorious error messages if you don’t).
I get error code 256 when I try to install a module
This usually means you are trying to uninstall or install to somewhere on the system where you don’t have permission. The best thing to do to get around this is to, in an interactive shell outside of the notebook, unset your python path, and use a version of pip that is under your control (and after added to your PYTHONPATH) to install the needed module. E.g.:
unset PYTHONPATH
wget https://bootstrap.pypa.io/get-pip.py
$HOME/anaconda3/bin/python get-pip.py
$HOME/anaconda3/bin/python -m pip install google
and then in your .bashrc make sure this path is hit first (note you may need to adjust the location
and version of python, this was for Anaconda3 installed in the default location)!
# in .bashrc
export PYTHONPATH=$HOME/anaconda3/lib/python3.6/site-packages:$PYTHONPATH
export PATH=$HOME/anaconda3/bin:$PATH
My password doesn’t work!
I ran into this issue with my password, and it seemed to be because I had set the password
with one version of jupyter, and then was using the second. To resolve this, I shut down
the server (and killed the job), and then deleted the $HOME/.jupyter folder and ran
jupyter notebook password again, both for Python 2 and Python 3, and set the same password
for both. I then started a new terminal and session on my local machine, and the changes
were picked up.
The terminal is hanging!
To make this automated, we issue commands from the start.sh script to capture output
from sherlock, using ssh sherlock to send the command. If it’s the case that your login
session has expired (or you got the wrong password), then you might have a password
prompt (that you can’t see) that looks like the terminal is hanging. If this seems to be
the case, try opening a new terminal window, and authenticating with sherlock again (ssh sherlock pwd should trigger the login authentication flow.)
Failed to setup local forwarding
If you have a hanging process (if you killed a session and now can’t recreate it) you might get an error
message about not being able to set up the port forwarding! What you want to do is use ps to list
processes with ssh, find the process id, and kill it. Here is an example.
# Here I'm searching for processes with ssh
$ ps aux | grep ssh
vanessa 749 0.0 0.0 44792 5216 pts/18 S 02:02 0:00 ssh -L 56143:localhost:56143 sherlock ssh -L 56143:localhost:56143 -N sh-113-14
vanessa 909 0.0 0.0 14228 984 pts/18 S+ 02:04 0:00 grep --color=auto ssh
vanessa 19987 0.0 0.0 49056 6608 pts/19 S+ Jul19 0:07 ssh -XY vsochat@login.sherlock.stanford.edu
vanessa 32442 0.0 0.0 44792 5260 pts/18 S 01:48 0:00 ssh -L 56143:localhost:56143 sherlock ssh -L 56143:localhost:56143 -N sh-ln01
See the last one, with pid 32442? That’s the one I want to kill:
$ kill 32442
# Is it gone?
$ ps aux| grep ssh
vanessa 749 0.0 0.0 44792 5216 pts/18 S 02:02 0:00 ssh -L 56143:localhost:56143 sherlock ssh -L 56143:localhost:56143 -N sh-113-14
vanessa 922 0.0 0.0 14228 988 pts/18 R+ 02:04 0:00 grep --color=auto ssh
vanessa 19987 0.0 0.0 49056 6608 pts/19 S+ Jul19 0:07 ssh -XY vsochat@login.sherlock.stanford.edu
[1]+ Exit 255 ssh -L 56143:localhost:56143 sherlock ssh -L 56143:localhost:56143 -N sh-ln01
It just exited! At this point, it’s easiest to run end.sh and then start.sh again.
bash end.sh singularity-jupyter
My notebook doesn’t have GPU
We have a simple method that checks for the --partition to be gpu, and if this is the case,
it appends --gres gpu:1. If you want to customize this further, just do so by changing
the entire PARTITION environment variable to include both the --partition and --gres (and
any other flags) of your liking. Take a look here
to see rules for usage, and your options.
There is some other problem, arggg!
Well what are you waiting for? Ask for help by opening an issue! or submitting a pull request.
It occurs to me, it’s pretty annoying to need to load modules, and still have broken dependencies. Would you be interested in a function like this to start an interactive container? And then allow it to select any container of your choosing? While this isn’t a container cluster proper, this is likely not too hard to do! Please let me know (@vsoch on Github) or Twitter) if this would be of interest to you, and consider it done!
Do you have questions or want to see another tutorial? Please reach out!
This series guides you through getting started with HPC cluster computing.
Slurm Manage, for submitting and reporting on job arrays run on slurm
A Quick Start to using Singularity on the Sherlock Cluster
Use the Containershare templates and containers on the Stanford Clusters
A custom built pytorch and Singularity image on the Sherlock cluster
Use Jupyter Notebooks via Singularity Containers on Sherlock with Port Forwarding
Use R via a Jupyter Notebook on Sherlock
Use Jupyter Notebooks (optionally with GPU) on Sherlock with Port Forwarding
Use Jupyter Notebooks on Sherlock with Port Forwarding
A native and container-based approach to using Keras for Machine learning with R
How to create and extract rar archives with Python and containers
Getting started with SLURM
Getting started with the Sherlock Cluster at Stanford University
Getting started with the Sherlock Cluster at Stanford University
Using Kerberos to authenticate to a set of resources